Time 축에서 압축하기 때문에 쓰기가 힘들것 같다. 중단
---
아래의 링크를 번역함
* representation이 임베딩같은 의미로 사용되는데, 이러한 임베딩을 만드는 것을
represent라고 동사화함. 번역할 떄는 표현이라 해두었음.
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state
A Visual Guide to Mamba and State Space Models
An Alternative to Transformers for Language Modeling
newsletter.maartengrootendorst.com
트랜스포머는 거대 언어 모델(LLM)의 성공의 큰 축을 담당합니다. 거의 모든 LLM이 트랜스포머를 사용하며 Mitstral 같은 오픈소스부터 ChatGPT같은 상용모델까지 널리 사용합니다.
LLM을 더 발전시키기위해 새로운 설계가 개발되었습니다. 심지어 트랜스포머보다 좋다고 하지요.
그것이 Mamba와 State Space Model(SSM) 입니다.

Mamba 는 Linear-Time Sequence Modeling with Selective State Spaces[1] 에서 제시되었습니다. 공식 구현과 모델 체크 포인는 이 리포지토리에서 확인 가능합니다.
https://github.com/state-spaces/mamba
GitHub - state-spaces/mamba
Contribute to state-spaces/mamba development by creating an account on GitHub.
github.com
해당 포스트 에서는 SSM 분야가 LLM에서 적용되는 것과 직관적으로 어떤식으로 개발되었는지 단계적으로 소개할 것입니다. 그 다음 어떻게 Mamba가 트랜스포머에 도전할 수 있는 지를 파악할 것입니다.
Table of Contents
- Part 1: 트랜스포머의 문제
- Part 2: The State Space Model (SSM)
- art 3: Mamba - 선택적 SSM
A Visual Guide to Mamba and State Space Models
An Alternative to Transformers for Language Modeling
newsletter.maartengrootendorst.com
A Visual Guide to Mamba and State Space Models
An Alternative to Transformers for Language Modeling
newsletter.maartengrootendorst.com
A Visual Guide to Mamba and State Space Models
An Alternative to Transformers for Language Modeling
newsletter.maartengrootendorst.com
\
A Visual Guide to Mamba and State Space Models
An Alternative to Transformers for Language Modeling
newsletter.maartengrootendorst.com
Part 1 : 트랜스포머의 문제
Mamba가 왜 흥미로운 구조인지 설명하기 위해서는 트랜스포머의 단점에 대해 짧게 짚고 넘어가야합니다..
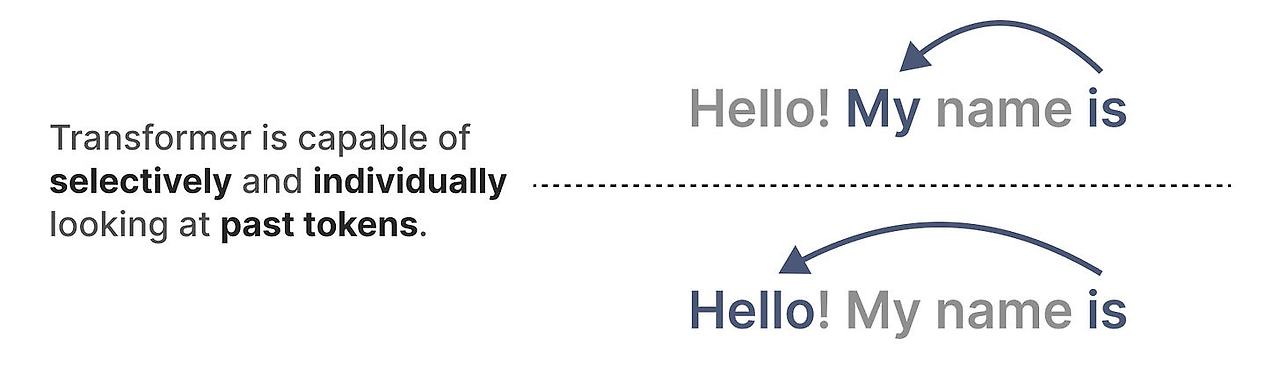
트랜스포머는 문자입력을 token으로 이루어진 sequence로 봅니다.
트랜스포머의 주된 장점은 어떤 입력을 받든지, 앞쪽의 token을 보고 표현을 얻을 수 있다는 것입니다.
트랜스포머의 핵심 요소
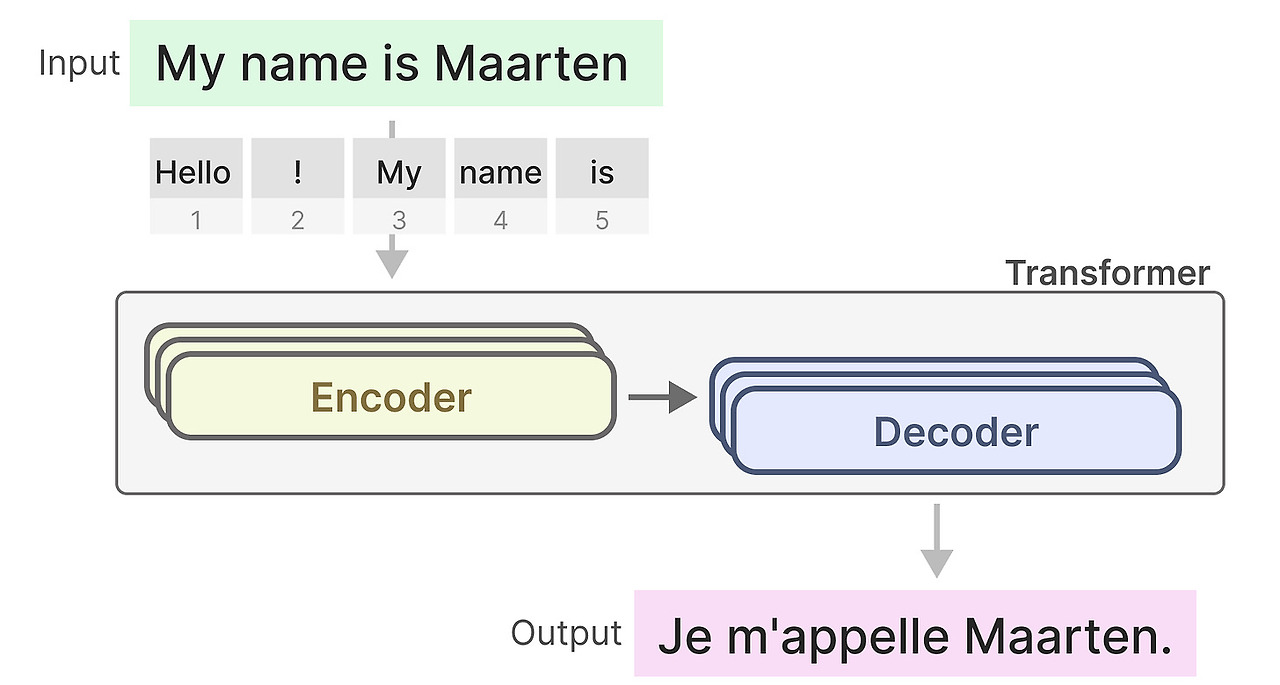
트랜스포머는 2가지 구조로 이루어져 있습니다. 텍스트를 표현는 인코더 블록과 텍스트를 생성하는 디코더 블록으로 이루어져 있습니다. 이 구조들이 함께 번역과 같은 작업에 사용됩니다.
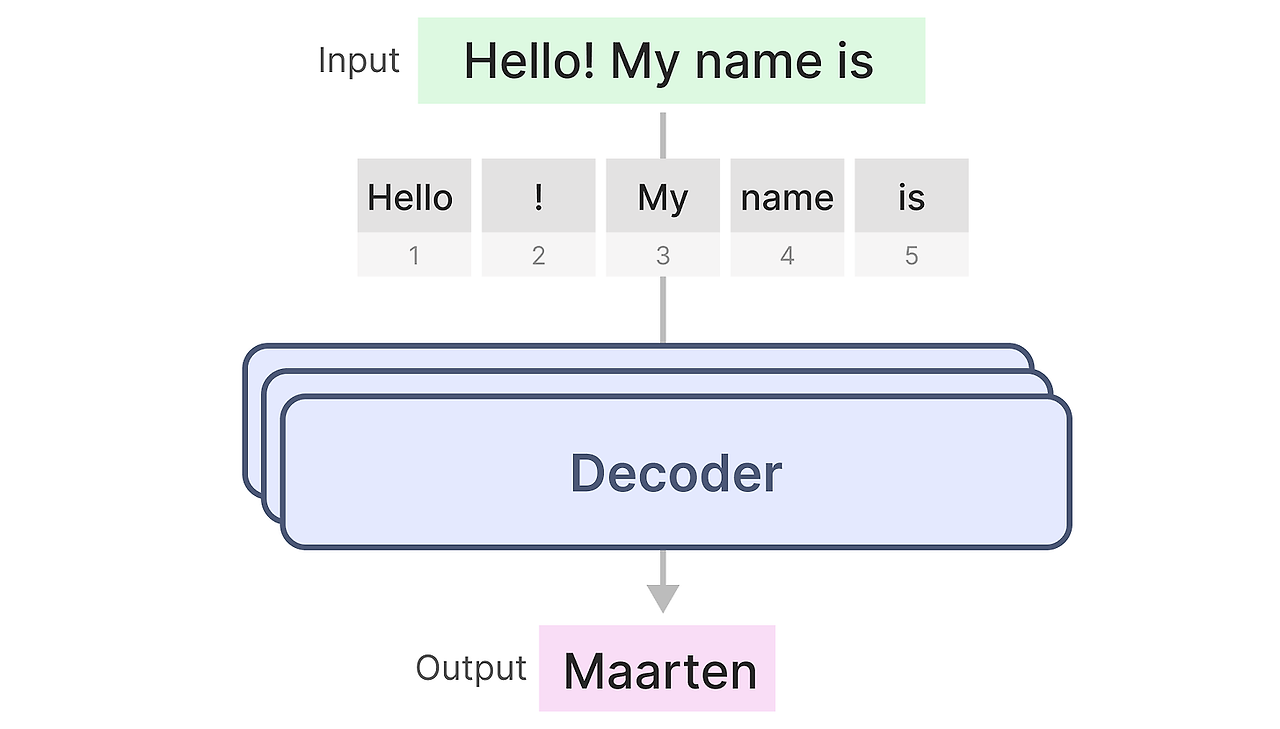
위의 구조에서 생성 모델을 만들기위해서 디코더 부분만을 차용할 수 있습니다. 이러한 모델을 Generative Pre-trained Transformer(GPT)라고 하며 입력 텍스트를 완성하기 위해 사용합니다.
이제 어떻게 동작하는 지 살펴봅시다.
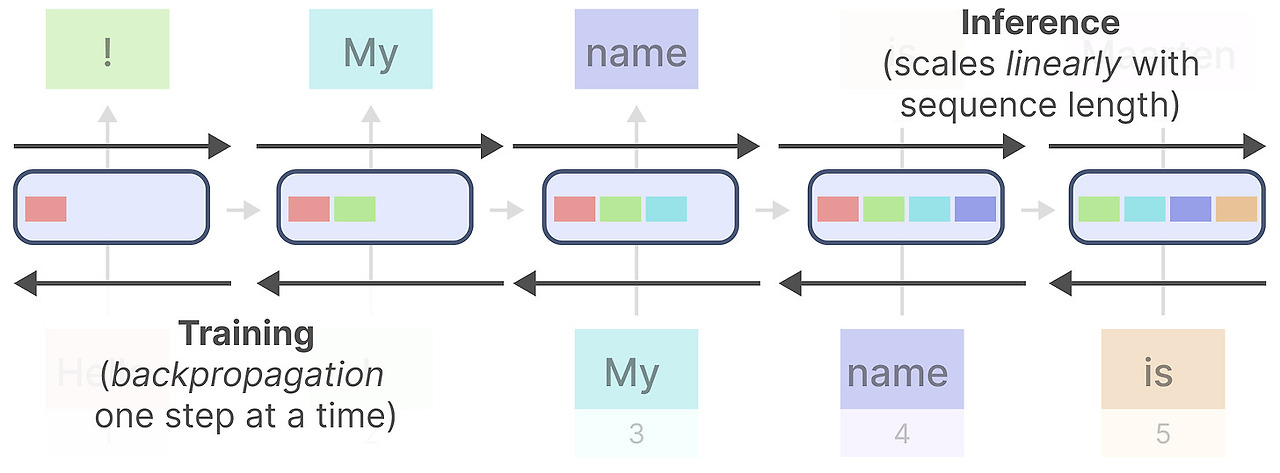
학습에서의 이점
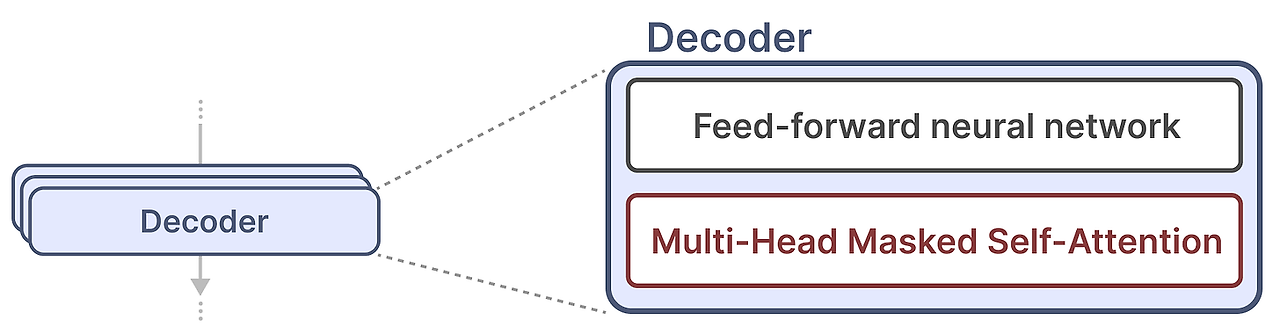
단일 디코더 블록은 2개의 요소로 구성되어 있습니다.
Masked self-attention과 그 뒤의 Feed-forward neural network 입니다.
Self-attention은 이 모델이 잘 동작하는 주원인입니다. 전체 sequence를 압축하지 않은 상태로 보기 때문에 빠른 학습이 가능합니다.
어떻게 동작하는 걸까요?
Self-attention은 각 토큰을 이전 토큰들과 비교하는 행렬을 만듭니다. 이 행렬의 가중치는 각 토큰 쌍에서 서로간의 연관성으로 결정됩니다.
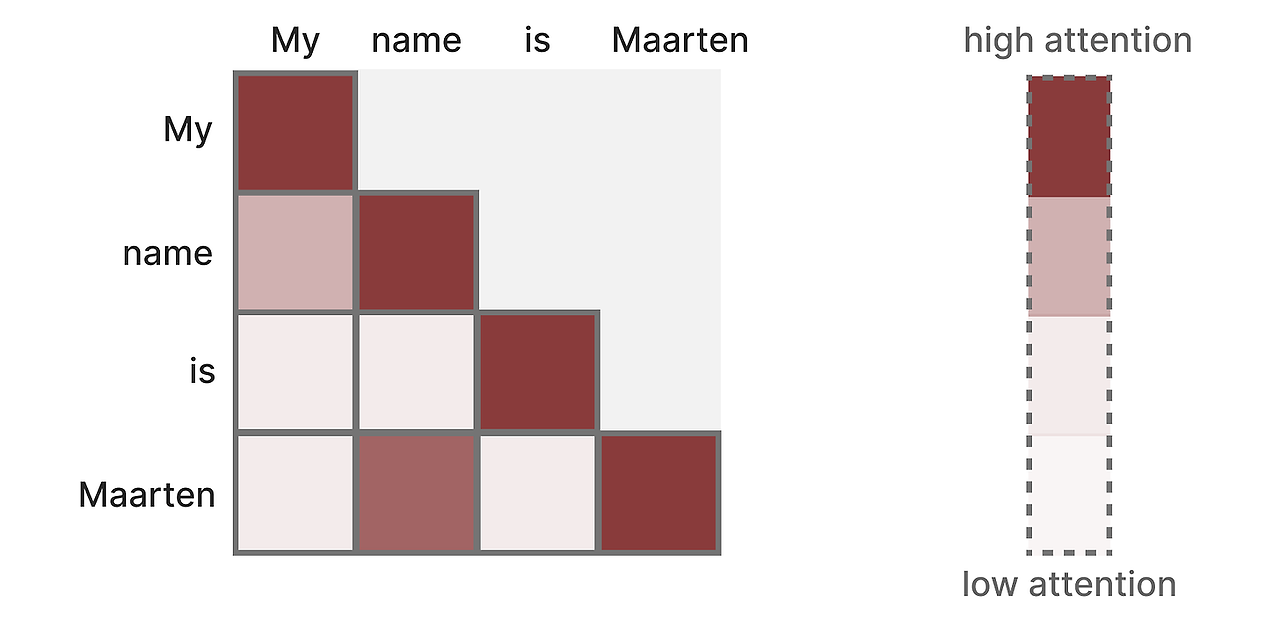
학습 과정에서, 이 행렬은 한번에 만들어집니다. "My" 와 "name" 간의 attention을 "name" 과 "is" 간의 attention 을 계산하기 전에 구할 필요가 없습ㄴ디ㅏ.
이 때문에 병렬화가 가능해져서 학습 속도를 엄청 높일 수 있습니다.
추론에서의 단점
단점도 있습니다. 다음 token을 만들 때, 우리는 전체 sequnece를 계산해야합니다. 이미 이전 token을 만들었더라도요.
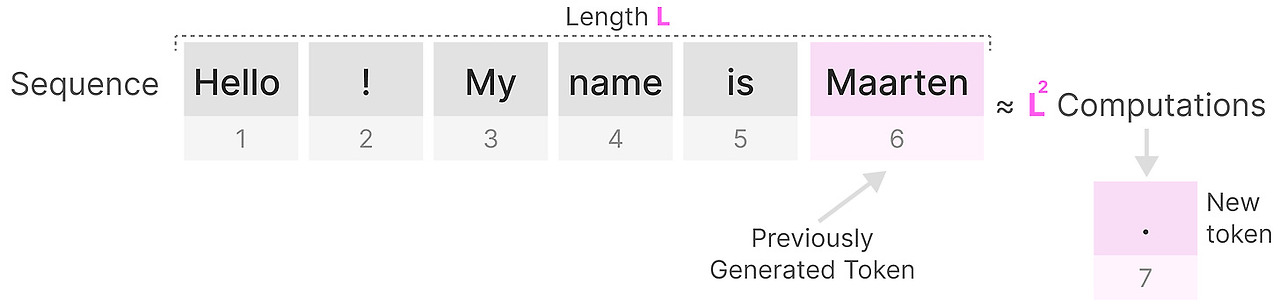
L길이의 sequence를 처리하려면 대략 L^2 의 계산이 필요하게 됩니다. sequence가 길어지면 기하급수적으로 연산량이 늘어납니다.

전체 sequence를 다시 계산하는 것은 트랜스포머의 주된 병목입니다.
어떤게 "전통적"인 Recurrent Neural Network가 이 문제를 해결하는 지 봅시다.
RNN이 해답인가?
Recurrent Neural Networks (RNN)은 sequnce 기반의 네트워크입니다.
매 스탭별로 2가지 입력을 받습니다. 시간 t의 입력과 시간 t-1의 hidden state입니다.
이 둘을 사용해서 다음 다음 hidden state와 출력을 생성합니다.
RNN은 loop 메커니즘을 가지고 있습니다. 이전 정보를 다음에 보내는데 사용하지요.
이를 풀어서 - unfold- 시각화하면 다음과 같습니다.
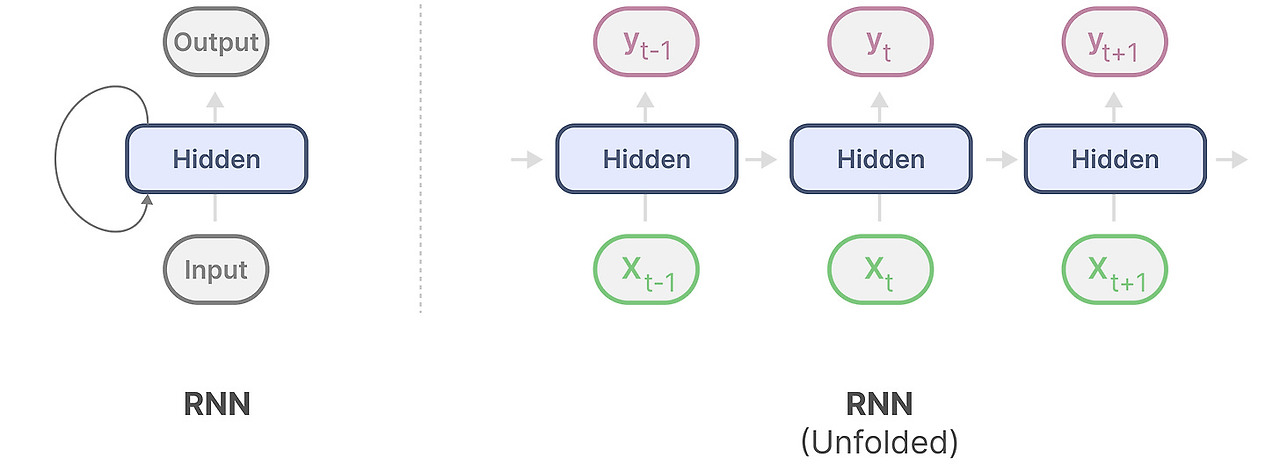
출력을 만들 때, RNN은 이전 hidden state와 현재 입력만을 고려합니다. 트랜스포머처럼 이전 계산을 반복하는 것을 방지합니다.
다른 말로는 RNN은 sequence 길이에 다른 선형적으로 상승하는 연산을 가집니다. 이론적으로 무한한 sequence 길이를 가질 수 있습니다.
이를 표현하기 위해서 RNN에 이전에 본 텍스트 입력을 넣어봅시다.
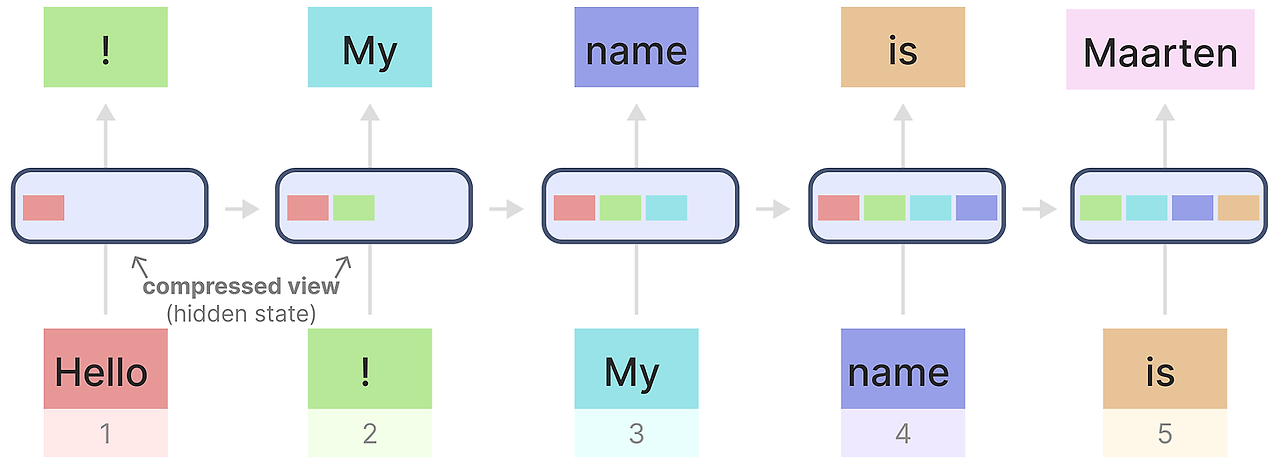
생략
생략

생략
Part 2: The State Space Model (SSM)
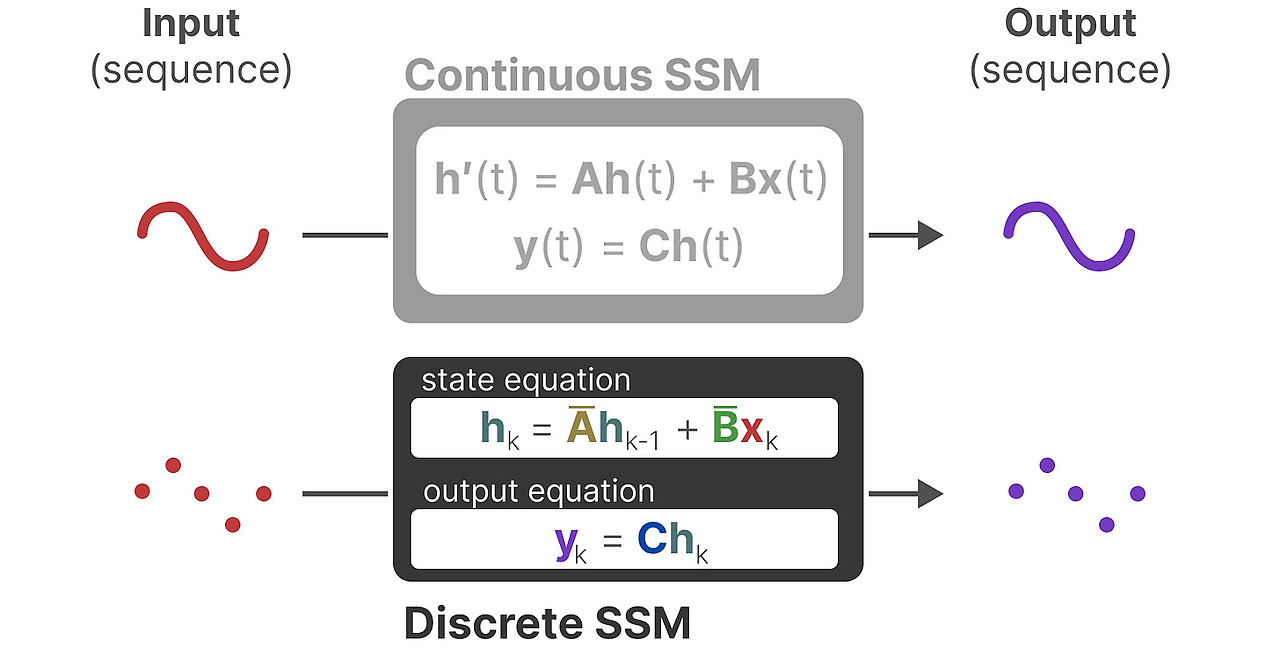
State Space Model(SSM)은 트랜스포머와 RNN처럼 sequence를 처리합니다. 여기서는 SSM의 기초와 어떻게 텍스트 데이터에 연관짓는지를 살펴봅니다.
State Space 란?
하나의 State Space는 한 시스템을 완전히 표현할 수 있는 최소한의 변수를 포함합니다. 시스템에서 가능한 상태를 정의함으로써 수학적으로 표현하는 것이죠.
간단히 해보죠. 우리가 미로를 통과해야한다고 상상해봅시다. 이 "state space"는 지도상의 가능한 지점(state)들입니다. 각 지점은 지도상에서의 고유한 위치와 특정한 상세(출구까지의 거리)를 나타냅니다.
이 "state space representation"은 간단히 묘사하면 이 지도입니다. 당신이 어디에 있는 지(현재 state), 어디로 갈 수 있는지(미래의 가능한 state 들), 어떻게 하면 다음 state로 가는 지(왼쪽이나 오늘쪽으로 이동하기 같은).
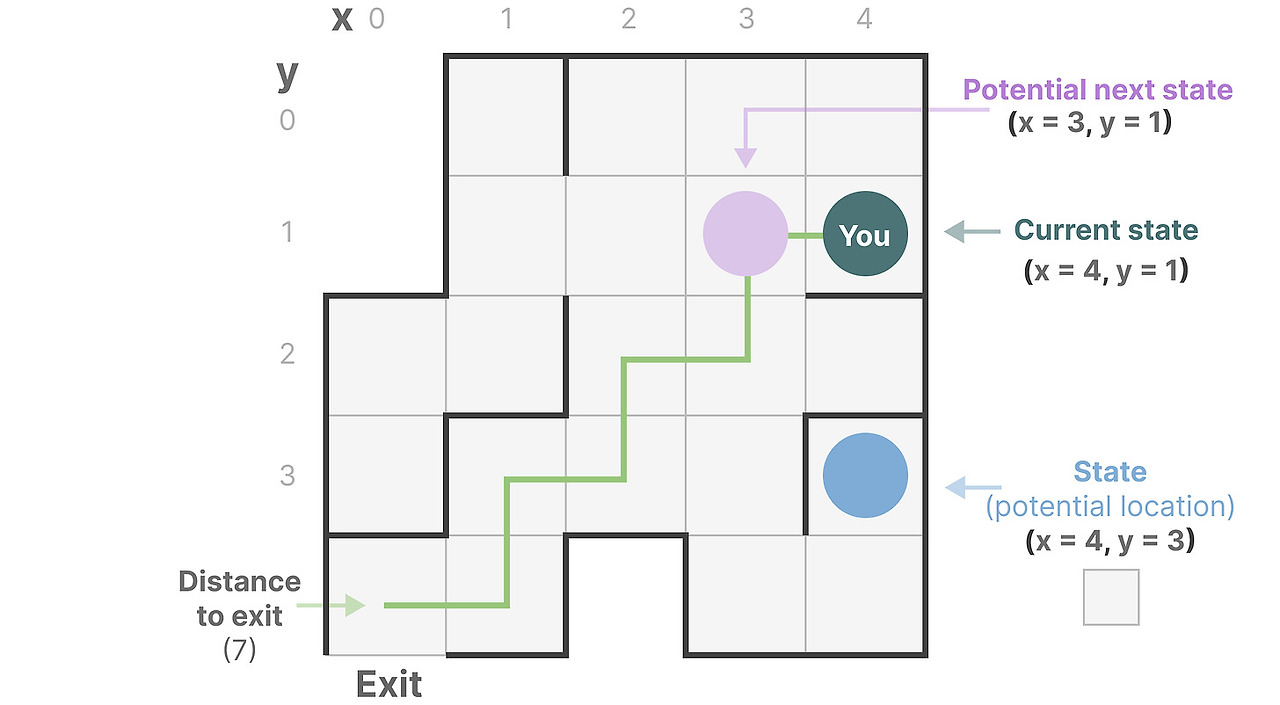
SSM이 이러한 동작원리를 추적하는 데 방정식과 행렬을 사용하지만 간단히 하자면 당신이 어디에 있고, 어디로 갈 수 있고, 어떻게 가는지를 추적하는 것 뿐입니다.
state를 묘사하는 변수들은 - 다음 예시에서 X,Y 축으로 표현- 출구와의 거리 같은 "state vector"를 표현합니다.
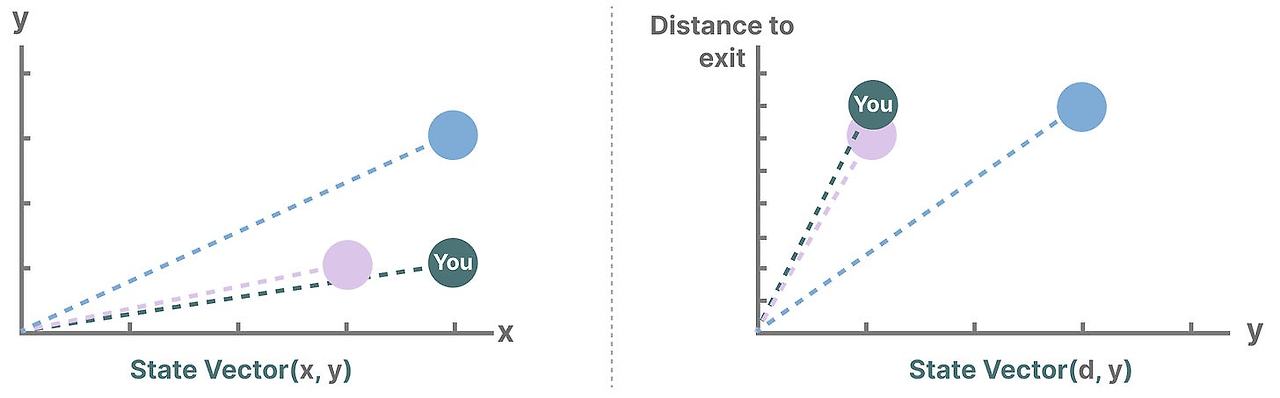
뭔가 익숙하지요? 언어 모델의 임베딩이나 벡터 또한 주로 입력의 sequnce의 "state" 표현하기 위해 사용되기 때문입니다. 예를 들어 현재의 위치(state vector)는 다음처럼 표현할 수 있습니다.
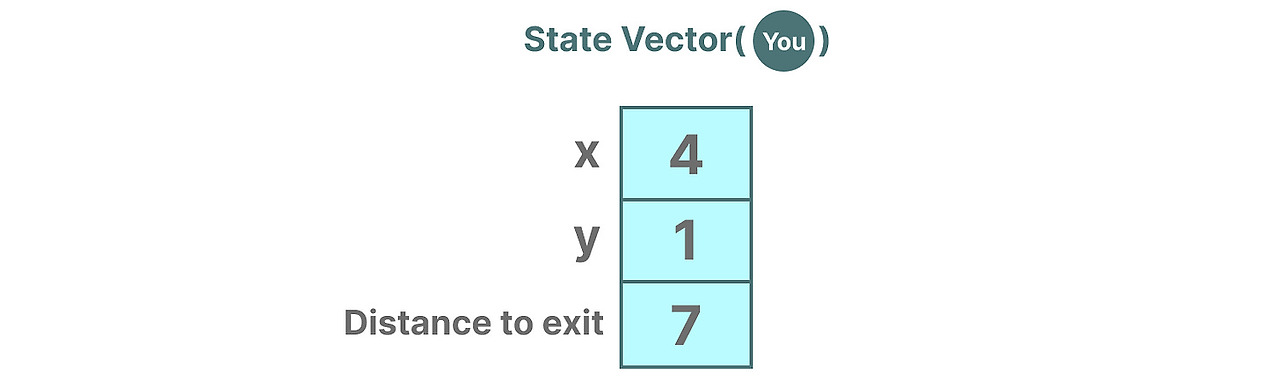
신경망의 관점에서 시스템의 "State"는 전형적으로 hidden state나 LLM의 context를 의미합니다. 다음 token을 생성하는 데 가장 중요한 요소지요.
State Space Model 이란?
SSM은 state를 묘사하고 다음 state가 어떤 입력에 영향을 받는지 예측하는데 사용됩니다.
전통적으로 시간 t 에서 SSM은
- 입력 sequence x(t)를 매핑 - 예 : 미로에서 아래로 이동했다
- latent state h(t) 를 표현 - 예 : 현재 좌표에서 출구까지의 거리
- 출력 sequence y(t)를 도출 - 예 : 출구로 가려면 왼쪽으로 가라
하지만 일반적인 SSM에서는 이산 sequence를 사용하는 대신에 연속 sequnce로 입출력을 사용합니다.

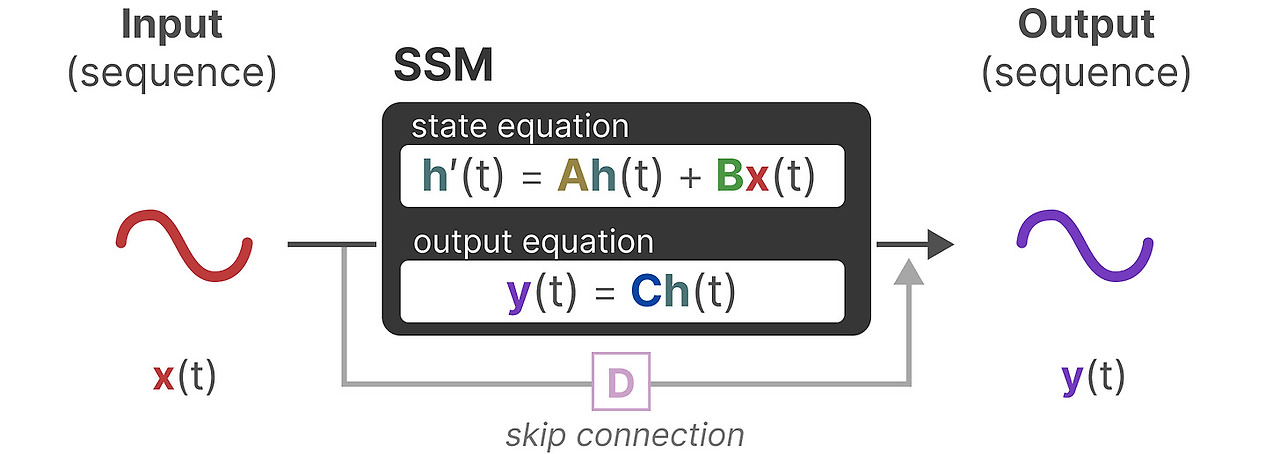
SSM은 3차원에서의 물체의 움직입 같은 동적 시스템을 가정하고 다음의 두 방정식을 통해서시간 t 에서의 state를 예측합니다.
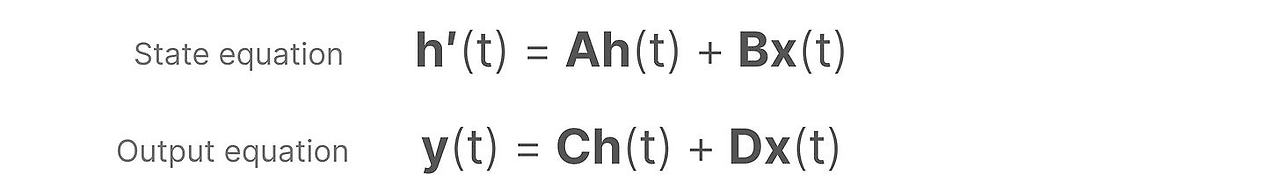
이 방정식을 풀어서, 관측된 데이터-입력과 이전 state- 기반으로 시스템의 상태를 예측하는 통계적 원리를 밝힐 수 있다고 가정할 수 있습니다.
최종 목적은 입력에서 출력으로 가는 h(t)를 찾는 것입니다.

이 두 방적식이 State Space Model의 핵심입니다.
좀 더 직관적으로 보기 위해서 위 식들을 색으로 구분하겠습니다.
state equation 은 입력이 어떻게 영향-행렬 B를 통해서 - 을 미쳐서 state가 어떻게 변화-행렬 A를 통해서-하는지 묘사합니다.
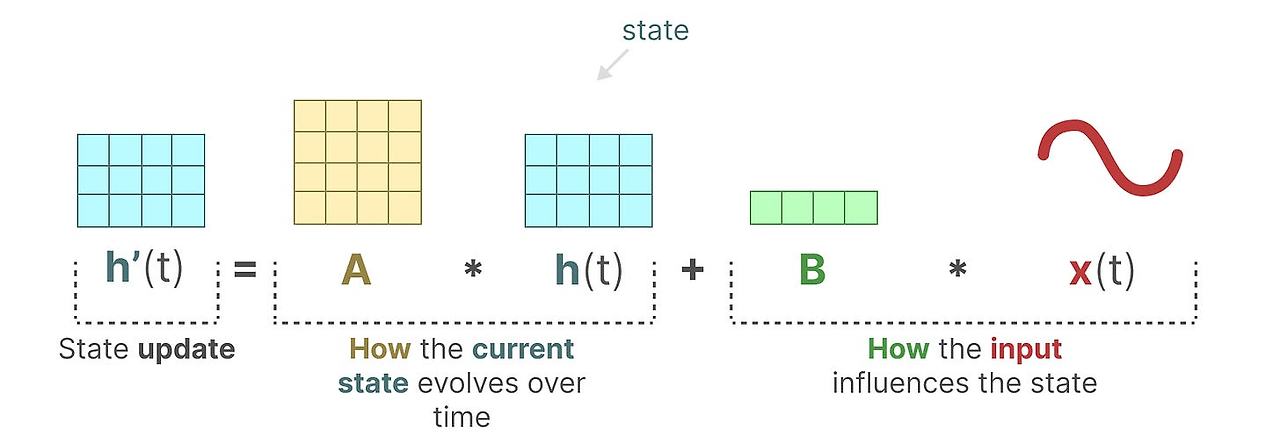
이전에 보았듯 h(t) 는 시간 t 에서의 latent state를 표현합니다. x(t)는 입력입니다.
출력 방정식은 어떻게 state가 출력으로 변환-행렬 C를 통해-되는지와 입력이 어떻게 출력에 영향-행렬 D를 통해서-을 주는 지 묘사합니다.
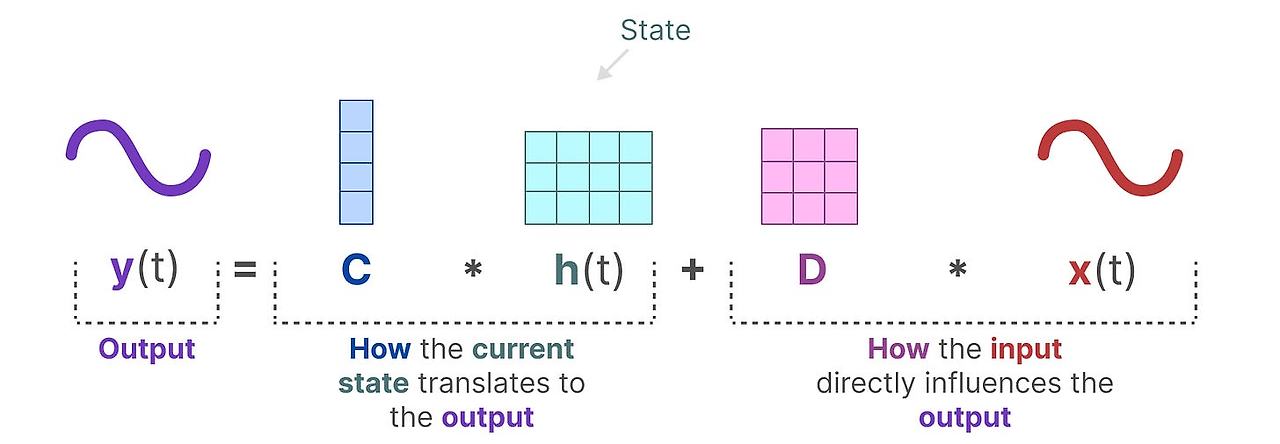
참고 : 행렬 A, B, C, D는 학습가능한 변수이기 때문에 parameter로 주로 불립니다.
이 두 방정식을 시각화하면 다음과 같은 구조를 얻습니다.
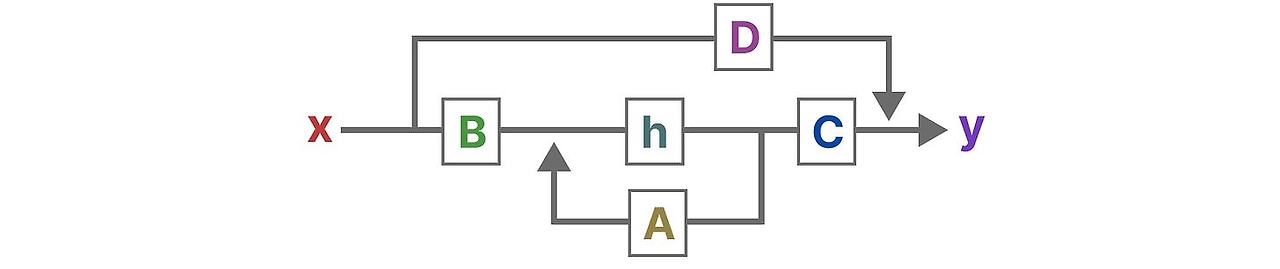
일반적인 step-by-step으로 이 행렬들이 학습과정에 영향을 미치는지 알아봅시다.
입력 신호 x(t) 가 있다고 합시다. 처음에 이 신호에 입력이 시스템에 얼마나 영향을 미치는지 나타내는 행렬 B가 곱해집니다.

갱신된 state-신경망에서 hidden state로 부르는- 는 환경에대한 핵심적인 "지식"을 담음 latent space 입니다. 우리는 여기에 내부 state가 어떻게 연결되었는지를 표현하는 행렬 A를 곱하게 됩니다.
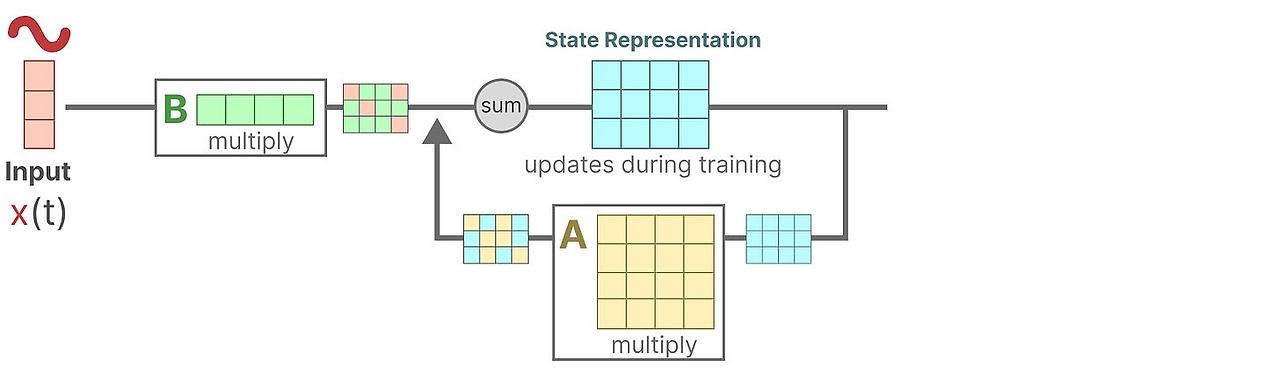
눈치챘다시피, 행렬 A는 state표현을 만들기 전에 적용되고 state 표현을 갱신한 다음에 행렬 A도 갱신되빈다.
그 다음에, state가 output으로 어떻게 변환되는 지를 나타내는 행렬 C를 사용합니다.
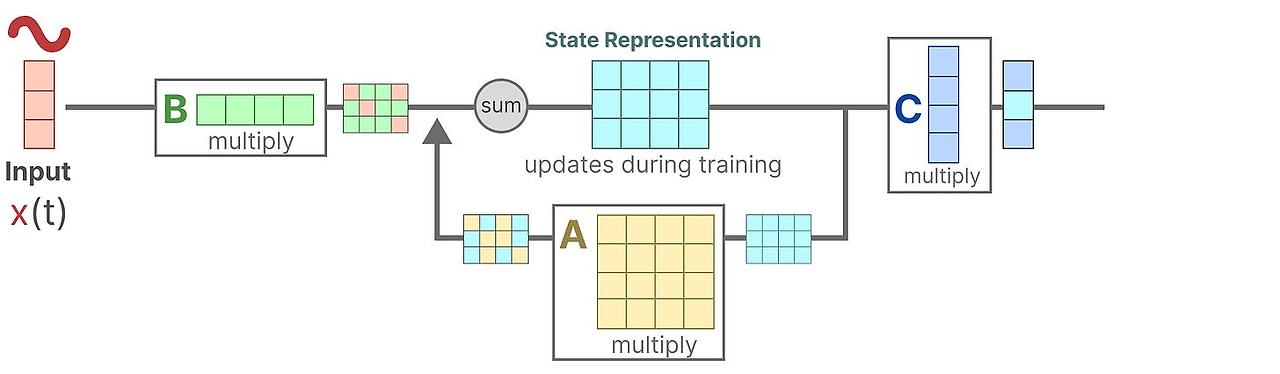
마지막으로 행렬 D를 통해서 입력신호가 출력에 직접적으로 어떤 영향을 주는 지를 보여줍니다. 이 것은 보통 skip-connection이라고 부르기도 합니다.
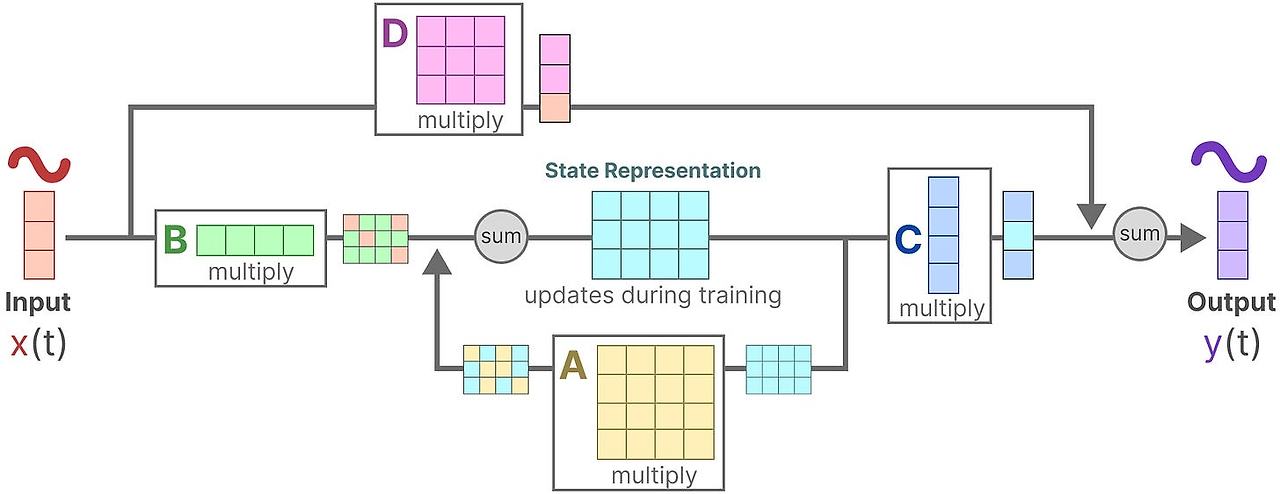
행렬 D는 skip-connection과 비슷하기 때문에, SSM 보통 skip-connection을 제외한 부분을 나타내기도 합니다.
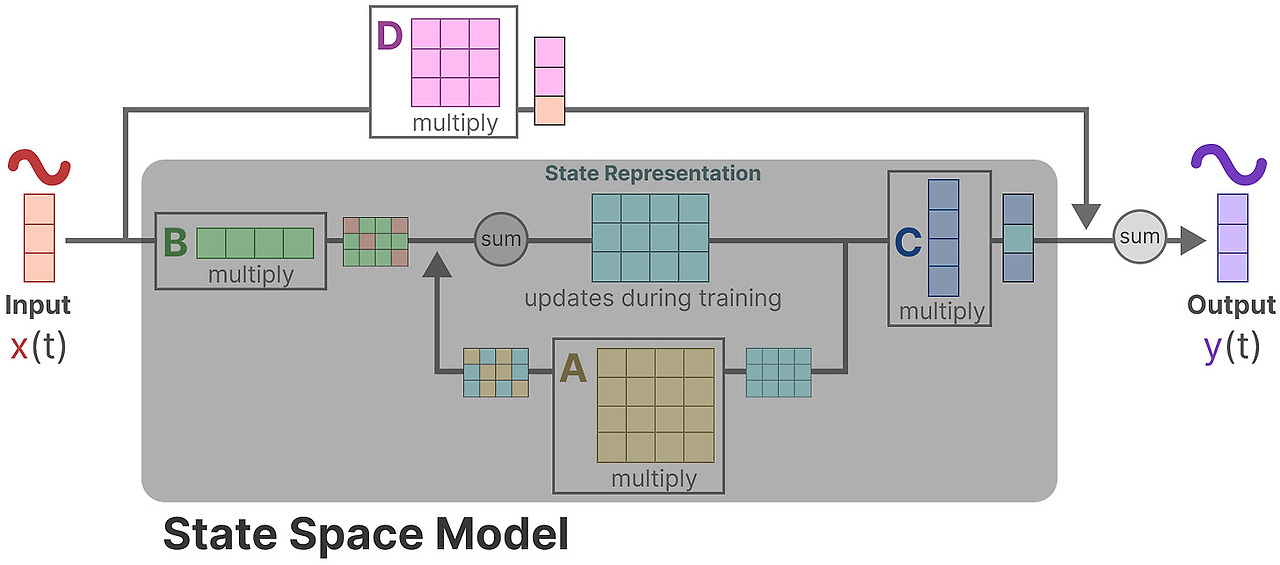
이전의 간략한 도식으로 돌아가서, SSM의 핵심요소인 행렬 A,B,C에 집중합니다.
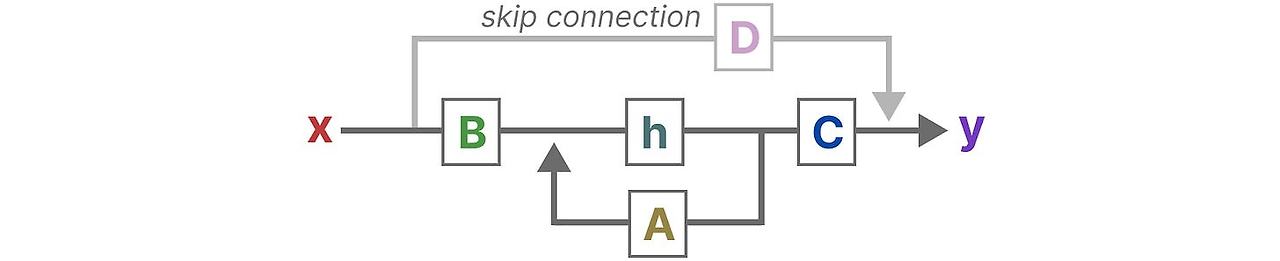
기존의 방적식을 행렬의 목적에 맞게 강조해서 표한하면 다음 처럼 됩니다.
위 방적식은 연속 입력을 다루기 때문에 SSM의 주된 표현은 연속-시간 표현입니다.
연속 신호에서 이산신호로
연속 신호에서 h(t)를 찾는 것은 분석적으로 힘든 일입니다.
더욱이, 우리는 보통 이산 신호를 입력으로 받기 때문에 모델을 이산화하기를 원하지요.
그러기 위해서 우리는 Zero-order hold 기법을 사용합니다. 다음과 같이 동작합니다.
우선 모든 시간에서 이산 신호를 받습니다. 새로운 값을 받을 때까지 보존합니다.
이 방식은 연속 신호 SSM을 다음처럼 만듭니다.
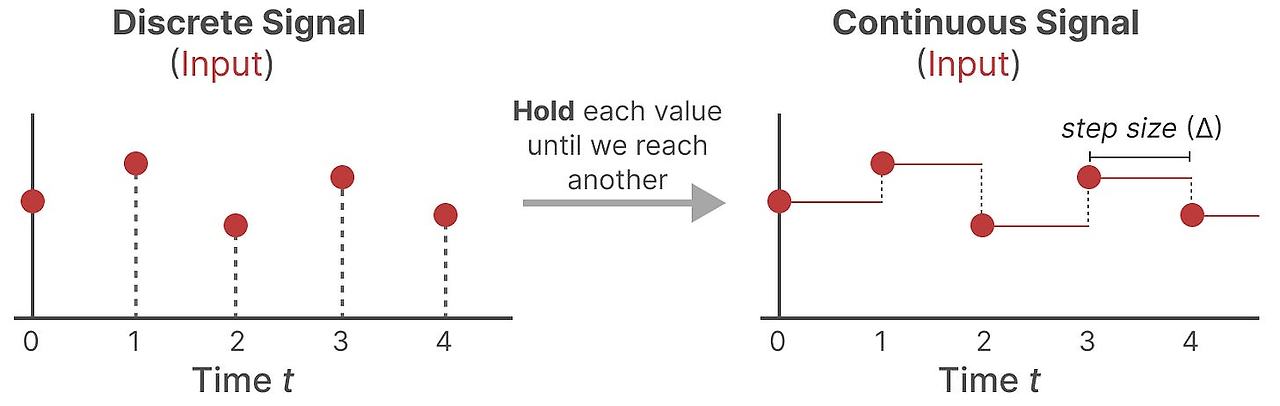
얼마나 오래 값을 보존할 지는 새로운 학습 가능한 매개변수(parameter) step size ∆ 가 결정합니다. 이 값은 입력의 해상도를 나타냅니다.
이제 우리는 time step에 따라서 값을 받게 됩니다.
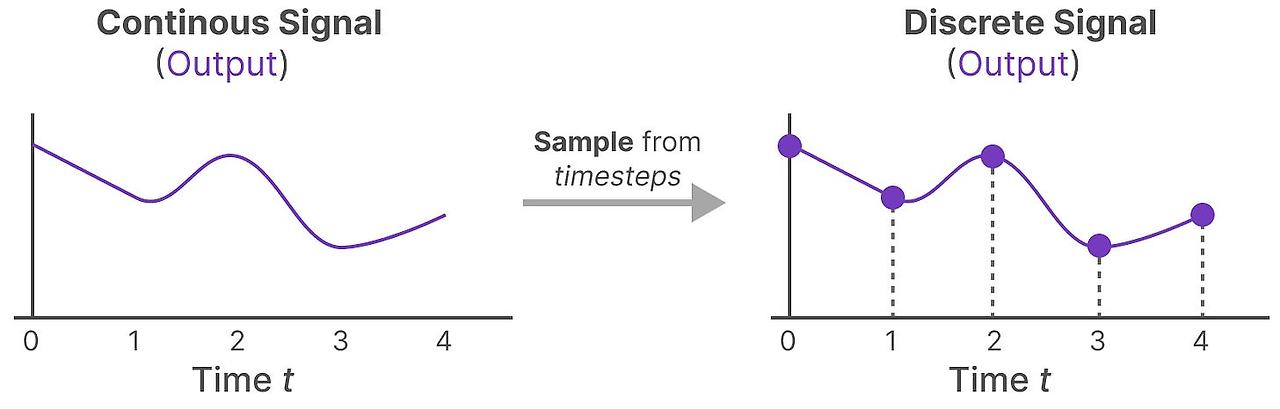
이산화된 출력이 되는 것이죠.
수학적으로, zero-order hold를 다음처럼 적용할 수 있습니다.
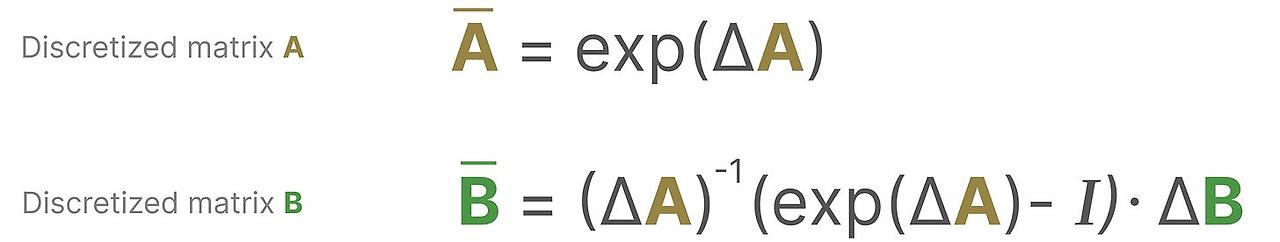
동시에 연속 SSM에서 이산 SSM으로 가기 위해서 function-to-function x(t)->y(t) 를 sequecne-to-sequence x_k -> y_k 를 사용합니다,
WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP WIP
재귀적 표현
합성곱 표현
3 표현
A 행렬의 중요성
Part 3: Mamba - 선택적 SSM
어떤 문제를 해결하려는가?
선택적으로 정보를 보존하기
탐색 연산
하드웨어-인식 알고리즘
Mamba 블록
[1] : Gu, Albert, and Tri Dao. "Mamba: Linear-time sequence modeling with selective state spaces." arXiv preprint arXiv:2312.00752 (2023). https://arxiv.org/abs/2312.00752
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution
arxiv.org
[2] :
[3] :
[4] :
[5] :
