Deep Neural Mel-Subband Beamformer for In-car Speech Separation
자세한 스펙 및 구성은 공개되지 않음
submit 이긴한데, 저자의 해당 모델 시리즈가 INTERSPEECH. ICASSP에 계속 등재되어 왔음
ABSTRACT
기존의 문제
DL 기반 빔포밍이 효과적이기는 하지만 각 주파수를 독립적으로 처리하는 Narrow Band로 수행한다. 이 때문에, 연산량이 많고 연산 시간이 길며, 실제 환경에서는 잘 동작하지 않게된다.
제시한 방식
- DL기반의 mel-subband spatial-temporal beamformer를 통해 차량환경에서 적은 연산량과 시간으로 음성 분리를 수행하는 모델을 제시한다.
- 기존의 subband 방식과는 다르게 mel-scale 기반의 subband를 통해서 정보가 많은 저주파 대역은 fine-grained로 정보가 적은 고주파 대역은 coarse-grainded로 처리한다.
- 각방향에 대해서 추정된 speech, noise subband의 공분산으로 frame-level의 빔포밍 weight를 출력한다.
- 차량의 loudspeaker에서의 echo를 억제한다.
1. INTRODUCTION
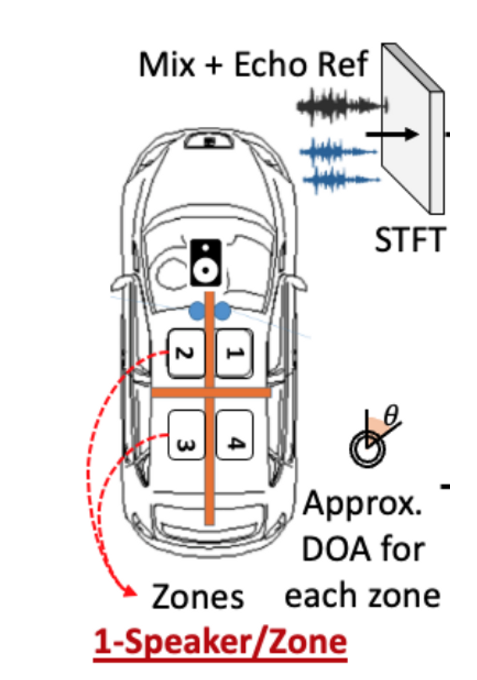
차량 시스템의 조건
DL과 음성기반 동작 기술은 차량산업에서 빠르게 발전하고 있다[1,2]. 이 환경에 사용되는 시스템은 몇가지 도전과제를 가진다.
- 다양한 분야의 전문가들에게 시연을 해야한다.
- 음성 향상[3,4], 음성 인식[5,6], 화자 인지[7], 음성 분리[8,9] 등
- 다양한 잡음 조건에서 강인하게 동작해야한다
- 제한된 차량 자원으로 빠른 추론을 해야한다.
현재 방식의 문제
현재는 대부분의 SOTA들이 DL기반의 마스크를 사용한 MVDR과[10 - 14] 이의 빈형이다. 이 방식은 다른 순순한 “black-box”인 신경망모델[15-19]보다는 비선형 왜곡이 적다. 하지만 기존의 마스크 기반의 모델은 residual noise가 크다는 단점이 있다.
이전 연구
본 연구진은 이전에 All-Deep-Learning MVDR(ADL-MVDR)[11], Generalized Recurrent Neural Network BeamFormer(GRNN-BF)[13] 로 이러한 이슈를 frame-level beamforming weight를 출력함으로써 streaming 시나리오에 적합하게 하였다. 유사하게 최근에는 Joint AEC and beamforming technique(JAEC-BF)[14] 로 비선형 echo를 다루었다.
문제점
하지만 이러한 방식은 느린 추론 시간과 큰 연산량을 요구한다. 각 주파수축에 대해서 독립적으로 수행하는 Narrow-band system[20-22] 이기 때문인데. 반면에 Full-band system은 모든 주파수를 동시에 수행하지만 전반적인 성능이 낮은 단점이 있다.
Xiaofel et al[23] (2019,)Narrow-band Deep Filtering for Multichannel Speech Enhancement
Narrow-band Deep Filtering for Multichannel Speech Enhancement
은 narrow band beamforming이 주파수 독립성으로 인해 over-fitting을 피하고 unseen에 대해 일반화가 잘 된다고 하였다.
제시된 방식
이러한 것들은 기반으로 챠랑내 음성 분리를 위한 end-to-end subband spatio-temporal RNN beamformer를 제시한다.
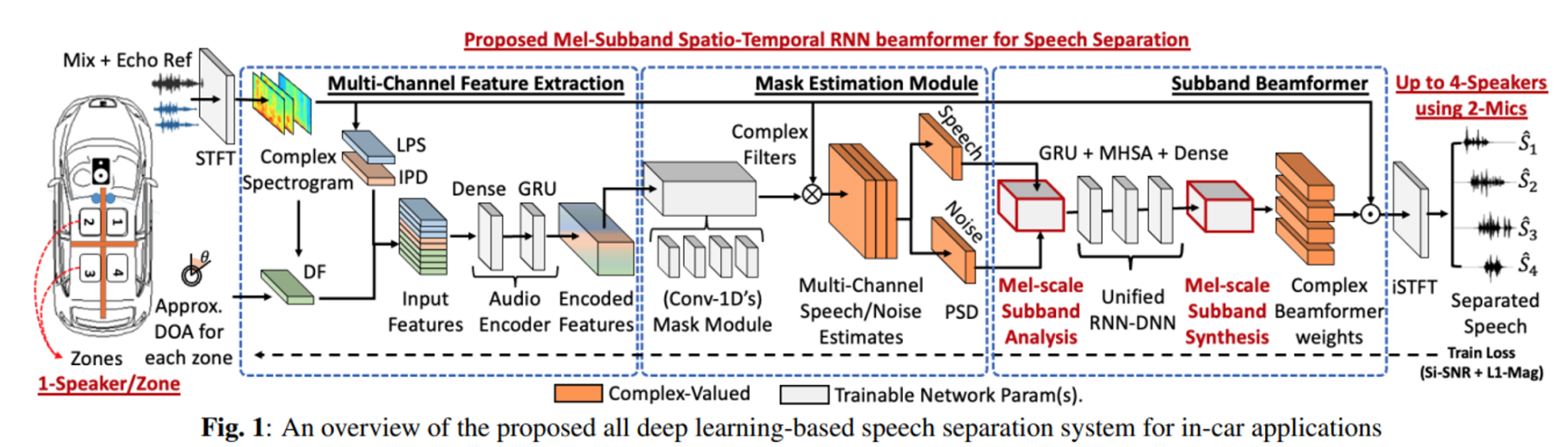
추가적으로 mel-scale 기반의 subband 선택 전략을 제시한다.
2. PROBLEM FORMULATION
입력
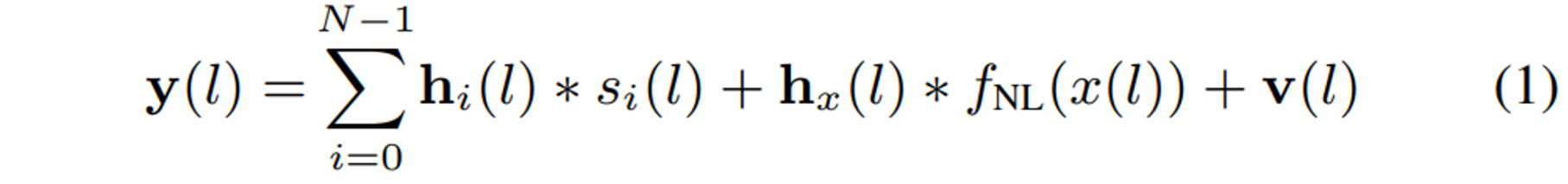
$N$ 명의 화자
$M$ 개의 마이크 어레이
$s$ : 음성
$x$ : loudspeaker 입력
$y$ : 마이크 입력
$l$ : time sample index
$f_{NL}$ : louadspeaker의 non-liearitiy
$\mathbf{h}_i,\mathbf{h}_x$ : 각 화자와 loudspeaker에 대한 RIR
$\mathbf{v}$ : 배경 잡음
시스템

- Reverberant clean speech를 추정함
3. BACKGROUND AND MOTIVATION
STFT domain
Narrow-band(NB)
각 주파수를 독립적으로 동일한 모델을 사용
장 : 최선의 spatial suppression [23]
단 : 연산량이 많고 느림
Full-band(FB)
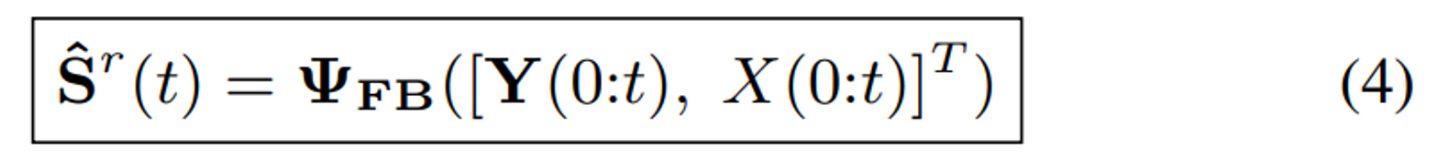
모든 주파수를 한번에 → flattend and concatenated
장 : 모든 주파수를 한 step으로 처리
단 : overffiting[23] → 실제 시나리오에서 안좋음
Subband
성능과 연산량 사이의 trade-off를 다루기 위해 사용
최근 연구[24] 에서는 split and merge 방식의 레이어로 성능향상을 보임
하지만 기존의 SB 방식은 uniform하게 band를 분할함. 하지만 저주파 대역에서 음성 정보가 많기 때문에 전체 성능을 낮출 것임. 이에따라 mel-scale 기반의 non-uniform한 subband를 사용
4. PROPOSED MEL-SUBBAND BEAMFORMER
구성
- multi-channel feature extraction
- mask estimation module
- subband beamformer
모델 입력
M 채널 데이터와 1채널 loudspeaker reference
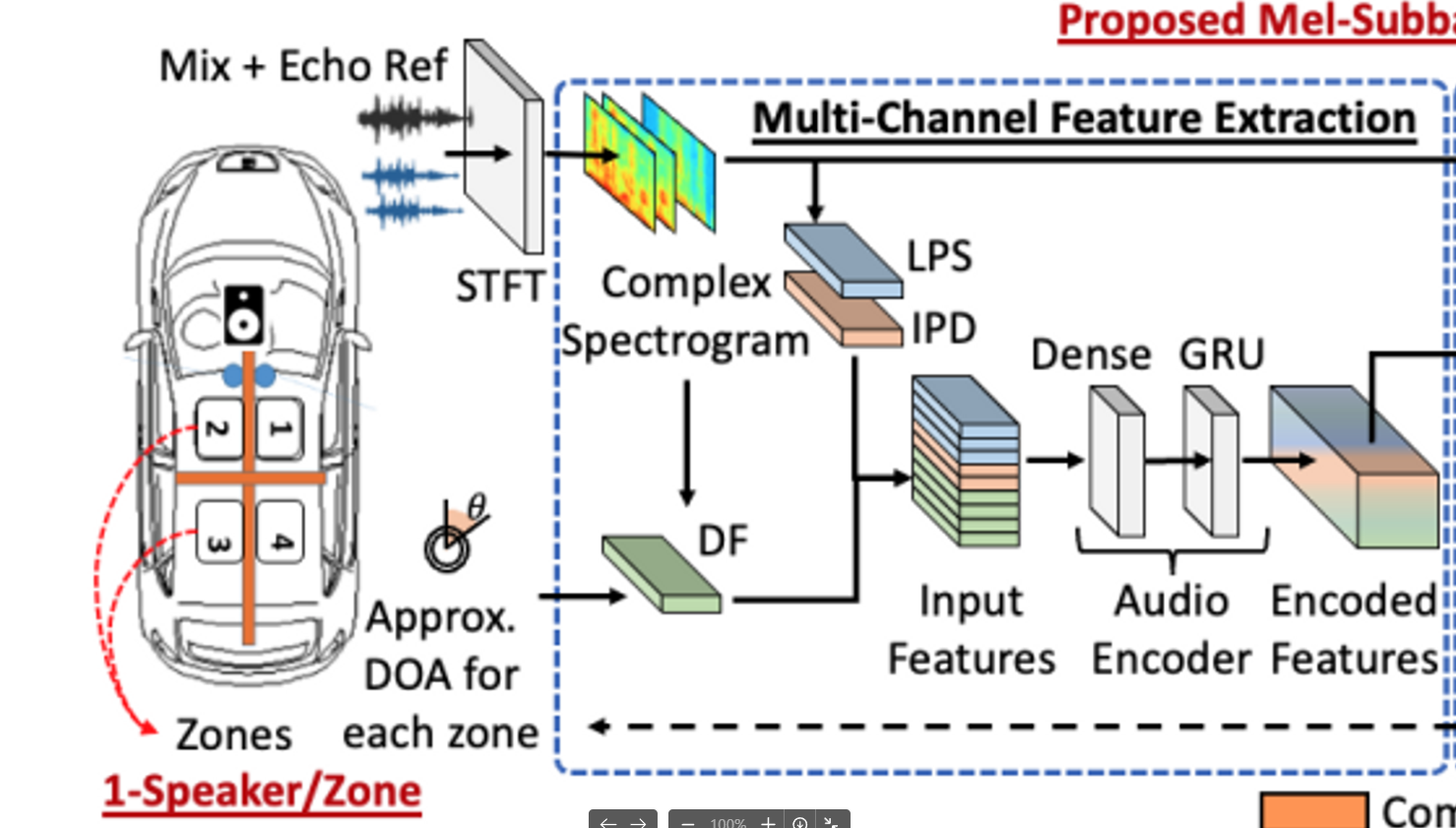
음향 샘플은 주파수 도메인으로 변환, STFT 연산을 수행하는 1-D conv layer를 사용.
log power spectrum(LPS)
inter-channel phase difference(IPD)
directional angle feature(DF)[13]
을 추출한 뒤에 CNN과 RNN을 거쳐서
input feature 생성
4.1 Mask estimation module
speech와 noise mask를 추정한다.
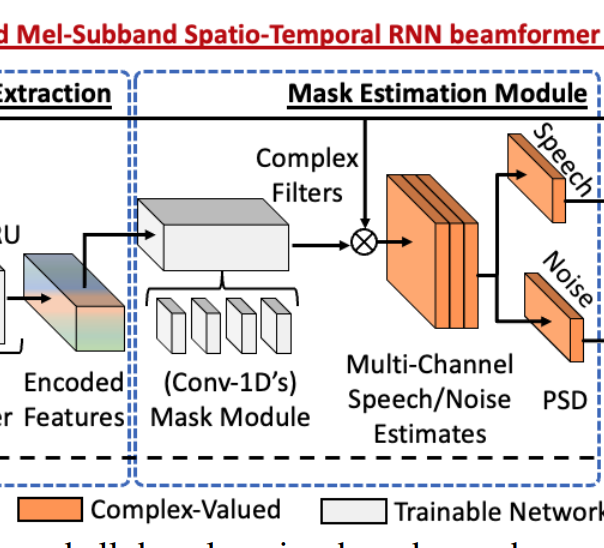
생성된 mask는 spatial covariance matrix(SCM)를 추정하는되 사용되고
이 SCM은 빔포밍 계수를 계산하는데 사용된다.
이전 연구에서 complex-valued ratio filter(cRFs)[25]가 다채널 SCM을 위해서는 더 좋은 성능을 낸다는 것을 보였다. 추가적으로 최근의 연구[14] 에서는 mixture와 echo 를 같이 사용하여 추정한 SCM이 빔포밍에는 더 좋은 것을 보였다.
따라서 1-D conv layers로 ‘cRFs’(mixture) 와 ‘cRFz’(echo)를 같이 추정한다.
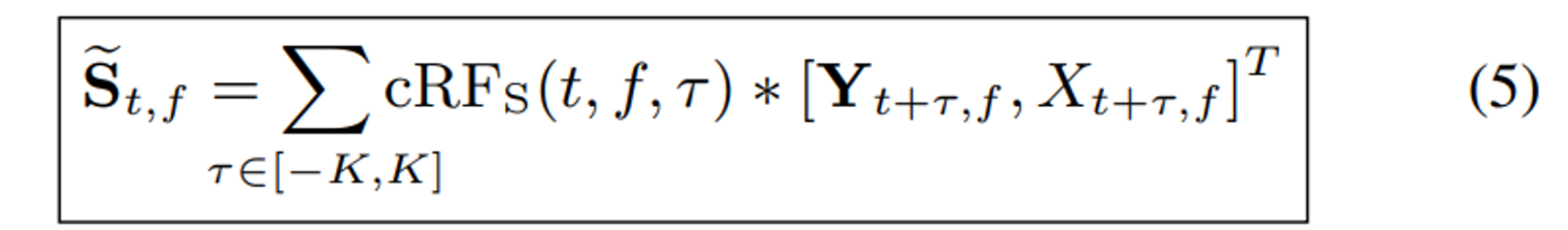
$\tau$ : filter-taps for cRF
cRFz도 같은 방식으로 계산
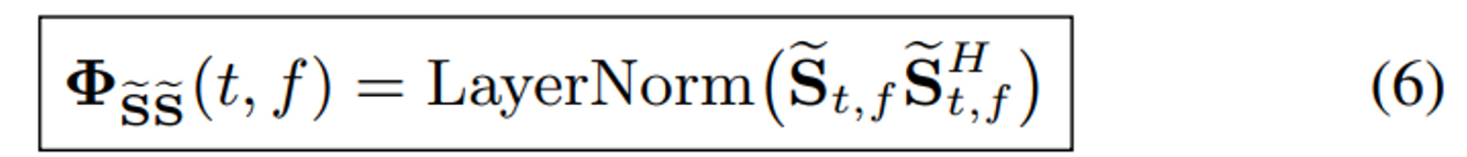
[13] 에서 언급했듯이, layer normalization을 speech와 noise에 수행해야 더 좋은 성는과 빠른 수렴을 보인다.
4.2 Sub-band beamformer
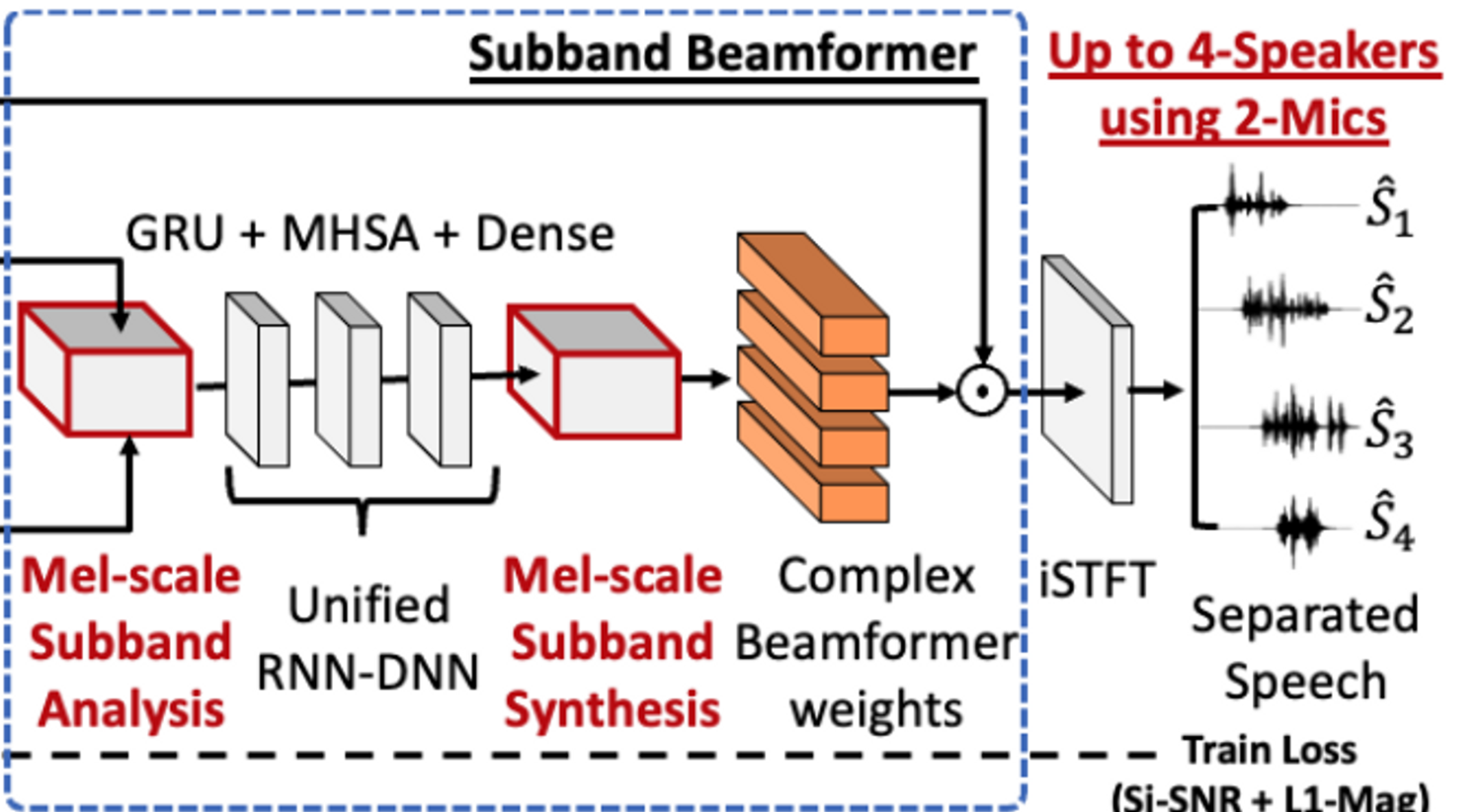
[13]과 유사하게 추정된 speech와 noise의 SCM을 입력으로 받아서 beamforming weight를 출력한다. 이를 위해 SCM을 flatten and concatenate하여 각각의 TF bin에 대한 $D_{\text{in}}$ 차원의 벡터를 만든다.
$$
\mathbf{\Phi_{\tilde{S}\tilde{S}}} \in \mathbb{R}^{T \times F \times D_{in}}
$$
아래에서 묘사한대로 SCM을 K 개의 subband로 나눈다.
Mel-scale subband analysis
전체 spectrum을 전통적인 mel-scale 대로 $K$-subband로 나눈다.
$K$ 개의 2-D conv로 학습가능한 analysis filter를 각 subband에 대해서 독립적으로 구성한다.
$$
\forall k \in [0,K-1]
$$
개별 밴드에 대해서 E 차원으로 변환이 된다.

noise SCM $\mathbf{\Phi_{\tilde{Z}\tilde{Z}}}$ 에 대해서 같은 처리를 수행한다.

그 다음 SB를 모든 subnand에 대해서 SB-level multi-frame beamforming을 수행하는 unfied RNN-DNN($\mathcal{F}_{RD}$) layer를 통과시킨다.
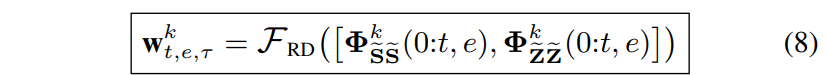
$\tau$ : the filter taps of the estimated beamformer weights
$\mathbf{w}^k_{t,e,\tau}$ : subband multiframe beamforming weights for each zone in the car
추가적오르 Multi-Head Self-Attention(MHSA)[26]을 적용한다.
Mel-scale subband synthesis
추정된 SB-level beamformer weights를 2D conv로 학습가능한 subband synthesis filter 통해서 full-band로 변환한다.
그 다음 출력은 주파수 축에 대해서 concat되어서 full-band multi-channel mulit-frame beamformer weight로 도출된다.
weight를 적용하고
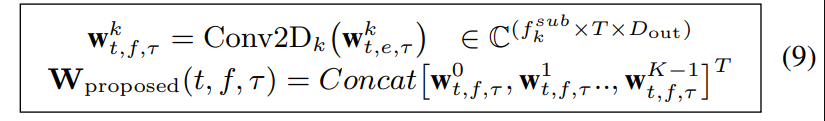
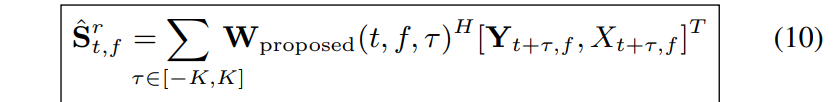
iSTFT 기능을 하는 1-D conv를 통과시켜서 추정된 time-domain 신호를 얻는다.
5. DATASET AND EXPERIMENTAL SETUP
5.1 Dataset
AISHELL-2[29] : AISHELL-2: Transforming Mandarin ASR Research Into Industrial Scale
와 AEC-Challenge[30] corpus를 사용,
10k 개의 차량환경에 대한 RIR 생성
2채널 11.8cm 간격의 선형 마이크.
RT60 0~ 0.6
추가적으로 AEC-Challenge[30]의 nonlinear distortion function을 사용하여 loudspeaker를 시뮬레이션
SNR : -40 ~ 15dB
signal to echo ratio : -10 ~ 10 dB
utterance 별로 데이터 생성
180K : 7.5L : 2K = train : dev : test
5.2 Experimental Setup
16kHz
n_fft = 512
n_hop = 256
4-second data
batch size : 12 ~ 24
SI-SNR[32] + MSE loss : 동일한 weight
모든 subband system은 파라매터가 5M 미만이되게 진행
30epoch
네트워크 전체에서
1-D conv 는 1x1 kernel
2-D conv는 3x1 kernel
cRF 추정의 filter tap은 3
MCMF의 filter tap은 5
제시된 모델을
- NB : traditional MVDR[10]
- NB : time-variant MVDR
- NB : GRNNBF[13]
- NB : robust NN based beamformer
- FB : LSTM+MHSA [27]
- FB : GRNNBf[13]
- FB : freq domain ConvTasNet
- SB : GRNNF
과 비교하였다.
6. RESULTS AND DISCUSSION
시뮬레이션한 test 데이터를 사용
Tencen API[33]로 ASR 성능 측정
1초 샘플에 대한 곱 연산 수행을 측정(MACs)

Subband Processing 에서 숫자는 subband의 수
traditional은 uniform
proposed 는 mel-scaled
Proposed Mel subband vs Traditional subband processing
mel-scaled로 subband를 구성한 것이 항상 unform 하게 한것보다 좋다.
Proposed Mel subband vs [NB & FB] processing
NB - GRNNBF가 모든 시스템보다 뛰어나지만
제시된 모델과 성능차이가 별로나지 않으면서 연산량이 5배이다.
FB는 연산량이 훨씬 적지만 그만큼 성능도 떨어진다.
In-Car Speaker Separation Demo
3화자 상황에서 실제 차량안 데이터를 취득해서 진행하였다.

https://vkothapally.github.io/Subband-Beamformer
현재 샘플 데이터 링크가 동작하지 않음
7. COLCLUSION
CPU연산량으로 동작이 가능한 ASR에서도 뛰어난 성능을 보이는 분리 네트워크를 제안하였다.
8. REFERENCES
[1] Fuliang Weng et al. “Conversational in-vehicle dialog systems: The past, present, and future”. In: IEEE Signal Processing Magazine 33.6 (2016), pp. 49–60.
[2] John HL Hansen et al. “" CU-Move": Analysis & Corpus
Development for Interactive In-Vehicle Speech Systems”.
In: Seventh European Conference on Speech Communication
and Technology. 2001.
[3] Timo Matheja and et al. “A dynamic multi-channel speech
enhancement system for distributed microphones in a car environment”. In: EURASIP Journal on Advances in Signal
Processing 1 (2013), pp. 1–21.
[4] Hiroshi Saruwatari et al. “Speech enhancement and recognition in car environment using blind source separation and
subband elimination processing”. In: (2003).
[5] Umit H Yapanel and John HL Hansen. “A new perspective on
feature extraction for robust in-vehicle speech recognition”.
In: Eighth European Conference on Speech Communication
and Technology. 2003.
[6] Joseph Caroselli and et al. Narayanan. “Cleanformer: A
microphone array configuration-invariant, streaming, multichannel neural enhancement frontend for ASR”. In: arXiv
preprint arXiv:2204.11933 (2022).
[7] Toshiro Yamada and et al. “In-vehicle speaker recognition using independent vector analysis”. In: 15th Intelligent Transportation Systems. IEEE. 2012, pp. 1753–1758.
[8] Tom O’Malley and et al. Narayanan. “A Universally-Deployable
ASR Frontend for Joint Acoustic Echo Cancellation, Speech
Enhancement, and Voice Separation”. In: arXiv preprint
arXiv:2209.06410 (2022).
[9] Tom O’Malley, Arun Narayanan, and et al. “A conformerbased asr frontend for joint acoustic echo cancellation,
speech enhancement and speech separation”. In: ASRU.
IEEE. 2021, pp. 304–311.
[10] Hakan Erdogan, John R Hershey, and et al. “Improved
MVDR beamforming using single-channel mask prediction
networks.” In: Interspeech. 2016, pp. 1981–1985.
[11] Zhuohuang Zhang, Yong Xu, and et al. “ADL-MVDR: All
deep learning MVDR beamformer for target speech separation”. In: ICASSP. 2021, pp. 6089–6093.
[12] Zhuohuang Zhang et al. “Multi-channel multi-frame ADLMVDR for target speech separation”. In: IEEE/ACM Transactions ASLP 29 (2021), pp. 3526–3540.
[13] Yong Xu et al. “Generalized spatio-temporal RNN beamformer for target speech separation”. In: arXiv preprint
arXiv:2101.01280 (2021).
[14] Vinay Kothapally et al. “Joint AEC AND Beamforming with
Double-Talk Detection using RNN-Transformer”. In: arXiv
preprint arXiv:2111.04904 (2021).
[15] Naohiro Tawara and et al. “Multi-Channel Speech Enhancement Using Time-Domain Convolutional Denoising Autoencoder.” In: INTERSPEECH. 2019, pp. 86–90.
[16] Panagiotis Tzirakis, Anurag Kumar, and Jacob Donley.
“Multi-channel speech enhancement using graph neural networks”. In: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
IEEE. 2021, pp. 3415–3419.
[17] Zhong-Qiu Wang and DeLiang Wang. “All-Neural MultiChannel Speech Enhancement.” In: Interspeech. 2018,
pp. 3234–3238.
[18] Bahareh Tolooshams et al. “Channel-attention dense u-net
for multichannel speech enhancement”. In: ICASSP 2020-
2020 IEEE International Conference on Acoustics, Speech
and Signal Processing (ICASSP). IEEE. 2020, pp. 836–840.
[19] Thomas Haubner and Walter Kellermann. “Deep LearningBased Joint Control of Acoustic Echo Cancellation, Beamforming and Postfiltering”. In: arXiv preprint arXiv:2203.01793
(2022).
[20] Xiaofei Li and Radu Horaud. “Narrow-band deep filtering
for multichannel speech enhancement”. In: arXiv preprint
arXiv:1911.10791 (2019).
[21] Changsheng Quan and Xiaofei Li. “Multi-Channel NarrowBand Deep Speech Separation with Full-Band Permutation
Invariant Training”. In: ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 2022, pp. 541–545.
[22] Changsheng Quan and Xiaofei Li. “Multichannel Speech
Separation with Narrow-band Conformer”. In: arXiv preprint
arXiv:2204.04464 (2022).
[23] Xiaofei Li and Radu Horaud. “Narrow-band deep filtering
for multichannel speech enhancement”. In: arXiv preprint
arXiv:1911.10791 (2019).
[24] Shubo Lv et al. “Dccrn+: Channel-wise subband dccrn with
snr estimation for speech enhancement”. In: arXiv preprint
arXiv:2106.08672 (2021).
[25] W. Mack and et al. “Deep filtering: Signal extraction and reconstruction using complex time-frequency filters”. In: IEEE
Signal Processing Letters 27 (2019), pp. 61–65.
[26] Ashish Vaswani et al. “Attention is all you need”. In: Advances in neural information processing systems 30 (2017).
[27] Rongzhi Gu et al. “End-to-end multi-channel speech separation”. In: arXiv preprint arXiv:1905.06286 (2019).
[28] Takuya Higuchi and et al. Kinoshita. “Frame-by-frame
closed-form update for mask-based adaptive MVDR beamforming”. In: ICASSP. IEEE. 2018, pp. 531–535.
[29] Jiayu Du and et al. Na. “Aishell-2: Transforming mandarin asr research into industrial scale”. In: arXiv preprint
arXiv:1808.10583 (2018).
[30] Kusha Sridhar, Ross Cutler, and et al. “ICASSP 2021 Acoustic Echo Cancellation Challenge: Datasets, Testing Framework, and Results”. In: ICASSP. 2021, pp. 151–155.
[31] Joachim Thiemann and et al. “The Diverse Environments
Multi-channel Acoustic Noise Database (DEMAND): A
database of multichannel environmental noise recordings”.
In: Proceedings of Meetings on Acoustics ICA. 2013.
[32] Yi Luo and Nima Mesgarani. “Conv-tasnet: Surpassing ideal
time–frequency magnitude masking for speech separation”.
In: IEEE/ACM TASLP 27.8 (2019), pp. 1256–1266.
[33] “Tencent ASR”. In: https://ai.qq.com/product/aaiasr.shtml
(2022).



