ABSTRACT
기존 방식들은 spectrum 과 magnitude를 서로간의 관계를 무시하고 분리해서 접근했다.
본 논문에선 Uformer, Unet기반의 dilated complex & real dual-path conformer network로 complex 와 magnitude domain에서 동시에 음성향상과 반향제거를 한다.
본 논문은 TA(Time Attention) 과 DC(Dilated Convolution)으로 log, global context를 얻고, FA(Frequency Attention) 으로 차원 정보를 모델링한다.
Encoder와 Decoder는 서로의 domain에서 정보의 상호작용을 한다. Encoder Decoder Attention으로 이 작용을 강화한다.
해당 모델은 객관적, 주관적 지표 모두에서 SOTA이며 Interspeech 2021 DNS Challenge 에서 상위 모델들의 성능을 다 이겼다.
1. INTRODUCTION
DNN 기반 speech enhancement 역사..
IRM(Ideal Ratio Mask)[1,2,3]...
→ CRM(Complex Ration Mask)[6]...
→ CRN(Convolution Recurrent network) and CSM(Complex Spectral Mapping)[7]...
→ DCCRN(Deep Complex Convoltuion Recurrenct Network)[8]...
으로 complex domain에서 mag, phase를 다 다루면서(CRM) 2020 DNS 실시간 트랙에서 1등을 하였다.
DCCRN+[9]는 subband processing 능력을 추가하고 multi task로 priori SNR 추정을 추가하였다.
음성 향상과는 별개로 반향 또한 어려운 과제이다. 반향과 non-stationary noise가 함께 있을 때 특히나 그렇다. 이전의 연구들은 다채널에서의 음성향상과 반향제거[10,11,12] 에서 좋은 성능을 보였지만 단일 채널에서는 상대적으로 아직도 힘든 과제이다. 단일채널에서의 연구들은 complex 와 mag 를 입력으로 사용하긴 했으나 서로의 상호작용은 없었다.
Conformer[13] 는 음성 인식에서 강한 contextual modeling 능력을 보여준다. 이는 두가지 모듈로 구성되는데, self-attention과 convolution이다.
이 모듈들은 음원 분리에서 좋은 성능을 보였다[14].
다른 transformer 기반 모델, e.g DPT-FSNET[15], TSTNN[16] 은 dual-path transformer를 적용하여 single-path에 비해 좋은 성능을 보였다.
TeCANet[17] 은 transformer를 context window내의 frame 간에 적용하였다.
더 좋은 contextual modeling을 위해 conformer와 dual-path를 조합하는 것은 직감적인 개념(instinctive idea)이다.
위에 언급햇떤 방식들에 영향을 받아서 Uformer를 제안한다.
- Contribution
- dialted complex & real dual-path conformer를 bottle-neck 에 적용시켰다. Time Attention 으로 local time dependency를 dilated Convolution으로 global time dependency를 Frequency Attention으로 subband information을 모델링하였다.
- hybrid encoder, decoder로 complex와 magnitude를 동시에 모델링하였다. 좋은 mag 추정은 phase 복원을 도와주며 그 반대도 마찬가지이다.
- skip connection 대신 encoder decoder attention을 활용하여 대응되는 layer간의 관련을 드러낸다(real the relevance)
Uformer는 2021 DNS challenge SDD-Net[18]의 MOS를 이겼다.
SDD
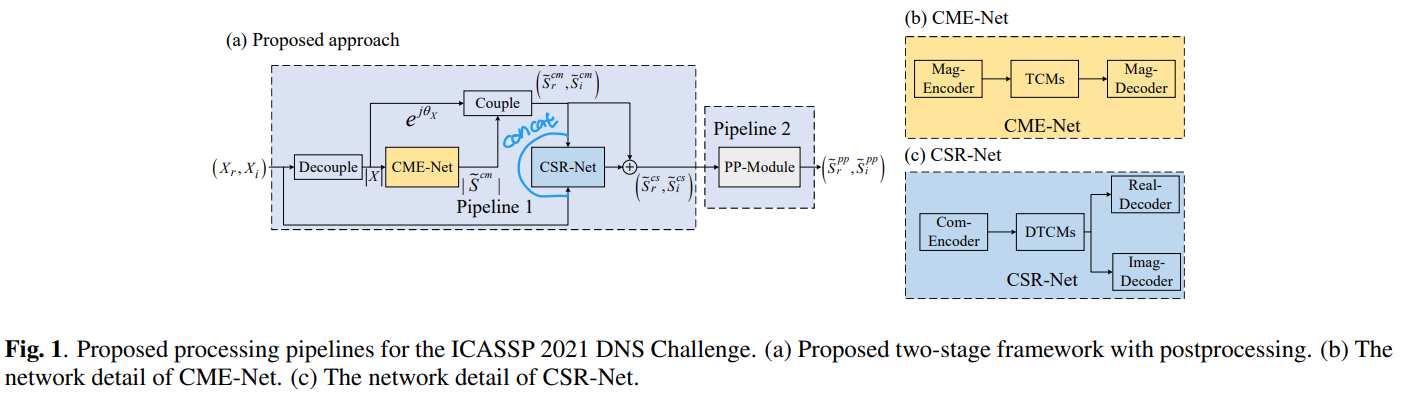
dual-path + Perceptnet postfilter
2. PROPOSED METHOD
2.1 Problem Formulation
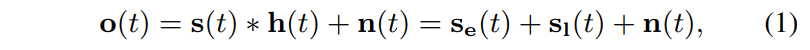

$_e$ : direct sound + early refelection
$_l$ : late reverberation
$n,N$ : noise
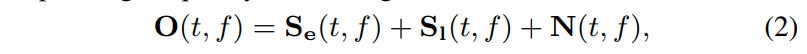
2.2 Complex Self Attention
real attention의 Query, Key, Value와 attention 다음과 같은데

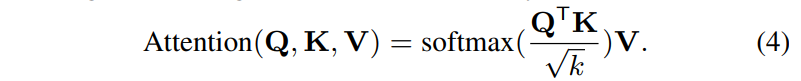
Complex Attention은 다음처럼 구한다.


2.3 Dilated Complex Dual-path Conformer
TA,FA,DC,FF 로 구성
구조는 real과 complex 가 동일
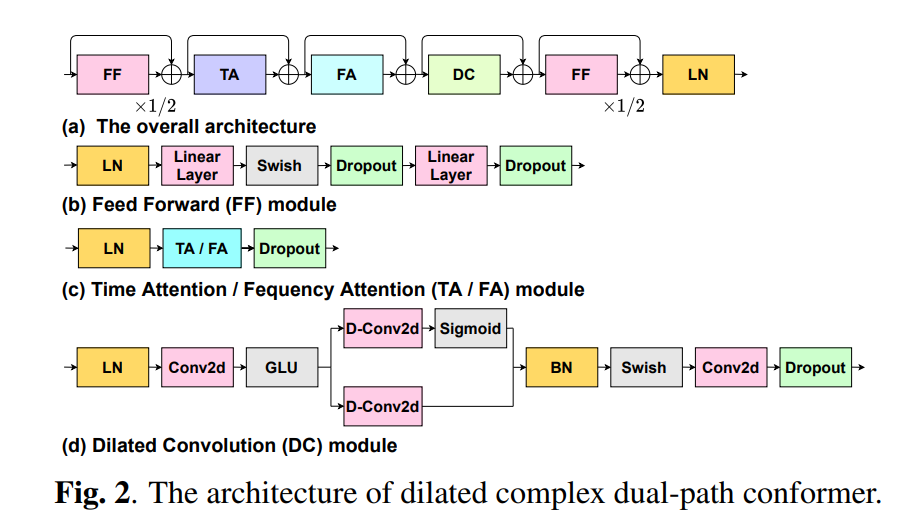
FF module만 기존 conformer와 동일
Conformer: Convolution-augmented Transformer for Speech Recognition
TA(Temporal Attention)
실내 상황에서 클릭이나 기침같은 잡음은 long contextual dependency가 없다. 반면에 입력 신호는 많은 delay와 attenuated copies 의 집합이기 때문에 제한된 구간에서 강한 correlation을 가진다.
따라서 local temporal relevance 정보를 잘 얻기 위해 Conformer에 영향을 받아서 TA로 전체 문장이 아닌 context window내의 frame을 활용하여 local temporal feature를 계산한다.
Fig 2(c)의 입력 $\text{TA} : \mathbf{X}_{TA}(t,f) \in \mathbb{C}^C$
c-frame expansion $\overline{\mathbf{X}_{TA}}(t,f) \in \mathbb{C}^{c \times C}$ 는 contextual feature로 생성된다.
$C$ : channel numbers of bottle-neck feature
- 문맥상 $c$ 는 contexutal frame의 수
입력을 통해서 (3) 을 통해 다음을 얻는다.
$\mathbf{Q}_{TA}(t,f) \in \mathbb{C}^{d_{TA} \times c}$
$\mathbf{K}_{TA}(t,f) \in \mathbb{C}^{d_{TA} \times 1}$
$\mathbf{V}_{TA}(t,f) \in \mathbb{C}^{c \times d_{TA}}$
Attention 은 다음과 같이 구한다.

$\mathbf{A}_{TA}(t,f) \in \mathbb{C}^{c \times 1}$
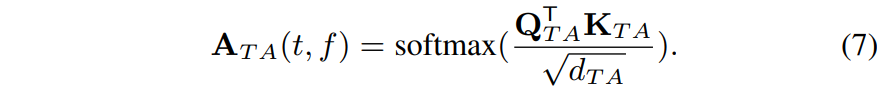
$\odot$ : element-wise multiplication
위 식으로 local temporal relevance information을 얻는다.
이 때, $Y_{TA}$ 뒤에 나오는 FC의 차원은 $X_{TA}$와 같다.
FA (Frequency Attention)
낮은 주파수 대역은 큰 에너지를 가지는 반면 높은 주파수 대역은 낮은 에너지를 가진다. 따라서 서로다른 주파수 대역에 대해서 다른 attention을 가져아한다.
제안하는 FA에서
$\mathbf{X}_{FA}(t,f) \in \mathbb{C}^{F \times C}$ 를 fig 2 (c) 의 입력으로 할 때,
$\mathbf{Q}_{FA}(t) \in \mathbb{C}^{d_{FA} \times F}$
$\mathbf{K}_{FA}(t) \in \mathbb{C}^{d_{FA} \times F}$
$\mathbf{V}_{FA}(t) \in \mathbb{C}^{F \times d_{FA}}$
이다.
FA의 결과 $\mathbf{Y}_{FA}(t) \in \mathbb{C}^{F \times d_{FA}}$ 는 일반적인 attention 식인 eq(4) 를 통해 구한다.
$\mathbf{Y}_{TA}$ 뒤에 따르는 FC의 차원은 $\mathbf{X}_{FA}$ 와 동일하다.

TasNet[19] 이 TCN 을 쌓아서 좋은 성능을 내었다. 본 논문은 TCN을 dual-path conformer에서 발전시켜서 사용한다.
위쪽은 D-Conv2d 의 dilation은 $1,2, ..., 2^{N-1}$ 이고
아래쪽은 $2^{N-1}, 2^{N-2},...,1$ 이다
$N$ : the cascaded layer number of dilated Conformer
2.4 Hybrid Encoder and Decoder

제안된 모델은 complex 와 magnitude 를 동시에 다룬다. 정보 교환을 위해서 complex-magnitude fusion 결과 $\hat{\mathbf{C}}_i$, $\hat{\mathbf{M}}_i$ 을 다음과 같이 구한다.
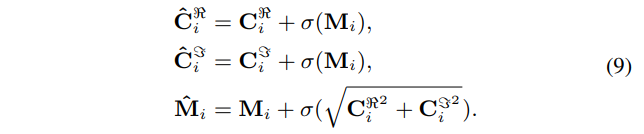
이를 매 unet layer 마다 수행한다.
2.5 Encoder Decoder Attention
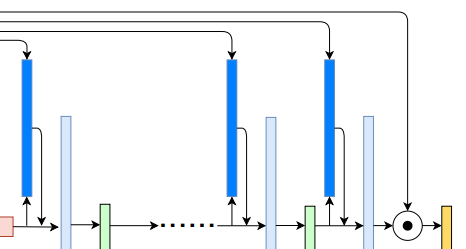
$\mathbf{E}_i$ : layer i 의 hybrid encoder
$\mathbf{D}_i$ : conformer 출력 또는 decoder layer i
더 높은 차원의 특징을 얻기 위해 Conv2d 를 우선 수행한다.
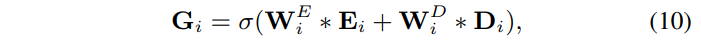
$\mathbf{W}^E_i,$$\mathbf{W}^D_i$ 각각의 convoltuion kernel
$\mathbf{G}_i$ 에 세번째 conv2d를 적용한 다음에 $D_i$ 로 Sigmoid attention mask를 곱해준다.

$\mathbf{W}^A_i$ : 세번째 convolution kernel
최종적으로 $\hat{\mathbf{D}}_i$ 와 $\mathbf{D}_i$를 채널 축으로 concat해서 다음 디코더에 넣는다.
2.6 Loss Function
CRM $\mathbf{H}_C$, IRM $\mathbf{H}_R$ 을 최종 디코더 출력으로 얻은 다음에 다음과 같이 향상된 신호를 생성한다.


그후 time,freq loss를 이용하여 학습한다.
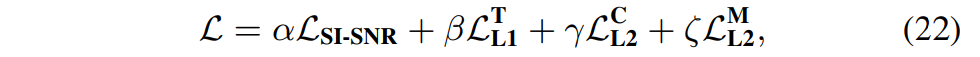
SI-SNR loss(SI-SDR, cosine-similarity), + time domain L1 loss, Complex domain L1 loss, Mag domain L1 loss 를 섞는다.
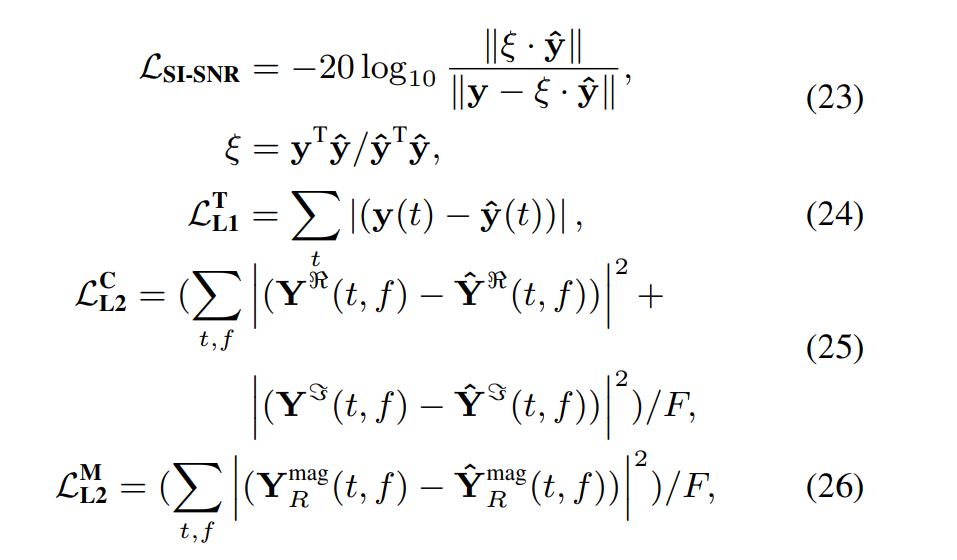
eq(18) 에서 complex 기반의 mag를 추정할 떄, mag 추정치를 섞었는데 실험시 complex만 하였을 떄, 왜곡이 많이 발생해서 성능저하가 극심하게 발생하였기 때문에다.
3.1 EXPERIMENTS AND RESULTS
3.1 Datasets
speech : LibriTTS[21], AISHELL-3[22], DNS challenge[23], MUSDB[24]
noise : MUSAN[25], DNS challenge, MUSDB, MS-SNSD[26] + 수집한 음악
train : 982 시간의 음성, 230 시간의 잡음 데이터
dev : 73시간 음성, 30시간 잡음
RIR를 위해 Image Method[27]사용,RT60은 0.2 ~ 1.2 초, early reflection은 50ms 이내
om-the-fly 로 4초씩 데이터 합성, SNR은 -5 ~ 15dB,
모델 평가를 위해 [-5,0],[0,5],[5,10]dB 의 시뮬레이션 데이터를 생성
overlap 없음.
DNS challenge blind test set은 evaluation으로 사용
3.2 Training Setups
nFFT = 512
window size 25ms
shift size 10ms
channel of encoder layers = [ 8, 16, 32, 64, 128, 128]
decoder는 그 반대로
time,freq 의 kernel 사이즈는 (2,5) 와 (1,2)
TA에서 frame expansion은 9 frame
non-causal model을 위해서 과거4 현재1 미래4 사용
causal을 의해서는 8과거 1현재
... 상세 파라매터
3.3 Experiments
....
complex domain 모델은 hybrid loss 사영
mag domain 모델은 SI-SNR로 학습
3.4 Results and Analysis
DNSMOS는 MOS를 시뮬레이션 한 지표[32]
12 명을 구성해서 MOS 측정
다른 모델의 지표들은 DNS challenge 제출지표

- 는 UFormer에서 모듈 하나씩 빼고 해본것
4. CONCLUSION
REFERENCE
[1] Yuxuan Wang, Arun Narayanan, and DeLiang Wang, “On
training targets for supervised speech separation,” IEEE/ACM
Transactions on Audio, Speech, and Language Processing, vol.
22, no. 12, pp. 1849–1858, 2014.
[2] Yong Xu, Jun Du, Li-Rong Dai, and Chin-Hui Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and
Language Processing, vol. 23, no. 1, pp. 7–19, 2014.
[3] Maximilian Strake, Bruno Defraene, Kristoff Fluyt, Wouter
Tirry, and Tim Fingscheidt, “Fully convolutional recurrent networks for speech enhancement,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
IEEE, 2020, pp. 6674–6678.
[4] D Wang and J. S Lim, “The unimportance of phase in speech
enhancement,” Acoustics Speech Signal Processing IEEE
Transactions on, vol. 30, no. 4, pp. 679–681, 1982.
[5] Kuldip Paliwal, Kamil Wojcicki, and Benjamin Shannon, “The ´
importance of phase in speech enhancement,” Speech Communication, vol. 53, no. 4, pp. 465–494, 2011.
[6] Donald S Williamson and DeLiang Wang, “Time-frequency
masking in the complex domain for speech dereverberation and
denoising,” IEEE/ACM Transactions on Audio, Speech, and
Language Processing, vol. 25, no. 7, pp. 1492–1501, 2017.
[7] Ke Tan and DeLiang Wang, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,” IEEE/ACM Transactions on Audio,
Speech, and Language Processing, vol. 28, pp. 380–390, 2019.
[8] Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang,
Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, “DCCRN:
Deep complex convolution recurrent network for phase-aware
speech enhancement,” Interspeech, pp. 2472–2476, 2020.
[9] Shubo Lv, Yanxin Hu, Shimin Zhang, and Lei Xie, “DCCRN+:
Channel-wise subband dccrn with snr estimation for speech enhancement,” arXiv preprint arXiv:2106.08672, 2021.
[10] Hideaki Kagami, Hirokazu Kameoka, and Masahiro Yukawa,
“Joint separation and dereverberation of reverberant mixtures
with determined multichannel non-negative matrix factorization,” in IEEE International Conference on Acoustics, Speech
and Signal Processing (ICASSP). IEEE, 2018, pp. 31–35.
[11] Henri Gode, Marvin Tammen, and Simon Doclo, “Joint multichannel dereverberation and noise reduction using a unified
convolutional beamformer with sparse priors,” arXiv preprint
arXiv:2106.01902, 2021.
[12] Lukas Pfeifenberger and Franz Pernkopf, “Blind speech separation and dereverberation using neural beamforming,” arXiv
preprint arXiv:2103.13443, 2021.
[13] Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang, “Conformer:
Convolution-augmented transformer for speech recognition,”
arXiv preprint arXiv:2005.08100, 2020.
[14] Sanyuan Chen, Yu Wu, Zhuo Chen, Jian Wu, Jinyu Li, Takuya
Yoshioka, Chengyi Wang, Shujie Liu, and Ming Zhou, “Continuous speech separation with conformer,” in IEEE International Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, 2021, pp. 5749–5753.
[15] Feng Dang, Hangting Chen, and Pengyuan Zhang, “Dptfsnet: Dual-path transformer based full-band and sub-band
fusion network for speech enhancement,” arXiv preprint
arXiv:2104.13002, 2021.
[16] Kai Wang, Bengbeng He, and Wei-Ping Zhu, “Tstnn: Twostage transformer based neural network for speech enhancement in the time domain,” in IEEE International Conference
on Acoustics, Speech and Signal Processing (ICASSP). IEEE,
2021, pp. 7098–7102.
[17] Helin Wang, Bo Wu, Lianwu Chen, Meng Yu, Jianwei Yu,
Yong Xu, Shi-Xiong Zhang, Chao Weng, Dan Su, and Dong
Yu, “TeCANet: Temporal-contextual attention network for
environment-aware speech dereverberation,” arXiv preprint
arXiv:2103.16849, 2021.
[18] Andong Li, Wenzhe Liu, Xiaoxue Luo, Guochen Yu, Chengshi
Zheng, and Xiaodong Li, “A simultaneous denoising and dereverberation framework with target decoupling,” arXiv preprint
arXiv:2106.12743, 2021.
[19] Yi Luo and Nima Mesgarani, “Conv-tasnet: Surpassing ideal
time–frequency magnitude masking for speech separation,”
IEEE/ACM Transactions on Audio, Speech, and Language
Processing, vol. 27, no. 8, pp. 1256–1266, 2019.
[20] Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R
Hershey, “SDR–half-baked or well done?,” in IEEE International Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, 2019, pp. 626–630.
[21] Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J Weiss,
Ye Jia, Zhifeng Chen, and Yonghui Wu, “LibriTTS: A corpus
derived from LibriSpeech for text-to-speech,” arXiv preprint
arXiv:1904.02882, 2019.
[22] Yao Shi, Hui Bu, Xin Xu, Shaoji Zhang, and Ming Li, “Aishell3: A multi-speaker mandarin tts corpus and the baselines,”
arXiv preprint arXiv:2010.11567, 2020.
[23] Chandan KA Reddy, Harishchandra Dubey, Kazuhito
Koishida, Arun Nair, Vishak Gopal, Ross Cutler, Sebastian
Braun, Hannes Gamper, Robert Aichner, and Sriram Srinivasan, “Interspeech 2021 deep noise suppression challenge,”
arXiv preprint arXiv:2101.01902, 2021.
[24] Fabian-Robert Stoter, Antoine Liutkus, and Nobutaka Ito, ¨
“The 2018 signal separation evaluation campaign,” in International Conference on Latent Variable Analysis and Signal
Separation. Springer, 2018, pp. 293–305.
[25] David Snyder, Guoguo Chen, and Daniel Povey, “MUSAN: A music, speech, and noise corpus,” arXiv preprint
arXiv:1510.08484, 2015.
[26] Chandan KA Reddy, Ebrahim Beyrami, Jamie Pool, Ross Cutler, Sriram Srinivasan, and Johannes Gehrke, “A scalable noisy
speech dataset and online subjective test framework,” arXiv
preprint arXiv:1909.08050, 2019.
[27] Jont B Allen and David A Berkley, “Image method for efficiently simulating small-room acoustics,” The Journal of the
Acoustical Society of America, vol. 65, no. 4, pp. 943–950,
1979.
[28] Dacheng Yin, Chong Luo, Zhiwei Xiong, and Wenjun Zeng,
“PHASEN: A phase-and-harmonics-aware speech enhancement network,” in Conference on Artificial Intelligence. AAAI,
2020, vol. 34, pp. 9458–9465.
[29] Yi Luo, Zhuo Chen, and Takuya Yoshioka, “Dual-Path RNN:
efficient long sequence modeling for time-domain singlechannel speech separation,” in IEEE International Conference
on Acoustics, Speech and Signal Processing (ICASSP). IEEE,
2020, pp. 46–50.
[30] Andong Li, Chengshi Zheng, Lu Zhang, and Xiaodong
Li, “Glance and gaze: A collaborative learning framework for single-channel speech enhancement,” arXiv preprint
arXiv:2106.11789, 2021.
[31] Andong Li, Chengshi Zheng, Renhua Peng, and Xiaodong Li,
“On the importance of power compression and phase estimation in monaural speech dereverberation,” JASA Express Letters, vol. 1, no. 1, pp. 014802, 2021.
[32] Chandan KA Reddy, Vishak Gopal, and Ross Cutler, “DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
IEEE, 2021, pp. 6493–6497.
[NLP 논문 구현] pytorch로 구현하는 Transformer (Attention is All You Need)



